The post CISA Issues Emergency Mandate as Critical 9.3 NetScaler Flaw “Bleeds” Admin Sessions appeared first on Daily CyberSecurity.
Related posts:
CitrixBleed 2: CVE-2025-5777 Joins CISA’s KEV Catalog Amid Active Exploitation Storm, PoC Available
Citrix Bleed 2: ReliaQuest Warns of Active Exploitation in NetScaler Gateway Vulnerability
Memory Leaks and Mixed Sessions: NetScaler’s Critical 9.3 CVSS Flaw Demands Immediate Action
For over a decade, GitHub has offered enterprise authentication using SAML (Security Assertion Markup Language), starting with our 2.0.0 release of GitHub Enterprise Server in November 2014. SAML single sign-on (SSO) allows enterprises to integrate their existing identity providers with a broad range of GitHub products, extend conditional access policies, and bring enterprise organization management to GitHub.
To ship this feature, we had to build and maintain support for the SAML 2.0 specif
For over a decade, GitHub has offered enterprise authentication using SAML (Security Assertion Markup Language), starting with our 2.0.0 release of GitHub Enterprise Server in November 2014. SAML single sign-on (SSO) allows enterprises to integrate their existing identity providers with a broad range of GitHub products, extend conditional access policies, and bring enterprise organization management to GitHub.
To ship this feature, we had to build and maintain support for the SAML 2.0 specification, which defines how to perform authentication and establish trust between an identity provider and our products, the service provider. This involves generating SAML metadata for identity providers, generating SAML authentication requests as part of the service provider–initiated SSO flow, and most importantly, processing and validating SAML responses from an identity provider in order to authenticate users.
These code paths are critical from a security perspective. Here’s why:
Any bug in how authentication is established and validated between the service and identity providers can lead to a bypass of authentication or impersonation of other users.
These areas of the codebase involve XML parsing and cryptography, and are dependent on complex specifications, such as the XML Signature, XML Encryption, and XML Schema standards.
The attack surface of SAML code is very broad, so the data that is validated for authentication and passed through users’ (and potential attackers’) browsers could be manipulated.
This combination of security criticality, complexity, and attack surface puts the implementation of SAML at a higher level of risk than most of the code we build and maintain.
Background
When we launched SAML support in 2014, there were few libraries available for implementing it. After experimenting initially with ruby-saml, we decided to create our own implementation to better suit our needs.
Over the years since, we have continually invested in hardening these authentication flows, including working with security researchers both internally and through our Security Bug Bounty to identify and fix vulnerabilities impacting our implementation.
However, for each vulnerability addressed, there remained lingering concerns given the breadth and complexity of root causes we identified. This is why we decided to take a step back and rethink how we could move forward in a more sustainable and holistic manner to secure our implementation.
So, how do you build trust in a technology as complex and risky as SAML?
Last year, this is exactly the question our engineering team set out to answer. We took a hard look at our homegrown implementation and decided it was time for change. We spent time evaluating the previous bounties we’d faced and brainstormed new ideas on how to improve our SAML strategy. During this process, we identified several promising changes we could make to regain our confidence in SAML.
In this article, we’ll describe the four key steps we took to get there:
Rethinking our library: Evaluating the ruby-saml library and auditing its implementation
Validating the new library with A/B testing: Building a system where we could safely evaluate and observe changes to our SAML processing logic
Schema validations and minimizing our attack surface: Reducing the complexity of input processing by tightening schema validation
Limiting our vulnerability impact: Using multiple parsers to decrease risk
Rethinking our library
When we reviewed our internal implementation, we recognized the advantages of transitioning to a library with strong community support that we could contribute to alongside a broader set of developers.
After reviewing a number of ruby SAML libraries, we decided to focus again on utilizing the ruby-saml library maintained by Sixto Martín for a few reasons:
This library is used by a number of critical SaaS products, including broad adoption through its usage in omniauth-saml.
Recent bugs and vulnerabilities were being reported and fixed in the library, showing active maintenance and security response.
This support and automation is something we wouldn’t be able to benefit from with our own internal implementation.
But moving away from our internal implementation wasn’t a simple decision. We had grown familiar with it, and had invested significant time and effort into identifying and addressing vulnerabilities. We didn’t want to have to retread the same vulnerabilities and issues we had with our own code.
With that concern, we set out to see what work across our security and engineering teams we could do to gain more confidence in this new library before making a potential switch.
In collaboration with our bug bounty team and researchers, our product security team, and the GitHub Security Lab, we laid out a gauntlet of validation and testing activities. We spun up a number of security auditing activities, worked with our VIP bug bounty researchers (aka Hacktocats) who had expertise in this area (thanks @ahacker1) and researchers on the GitHub Security Lab team (thanks @p-) to perform in-depth code analysis and application security testing.
This work resulted in the identification of critical vulnerabilities in the ruby-saml library and highlighted areas for overall hardening that could be applied to the library to remove the possibility of classes of vulnerabilities in the code.
But is security testing and auditing enough to confidently move to this new library? Even with this focus on testing, assessment, and vulnerability remediation, we knew from experience that we couldn’t just rely on this point-in-time analysis.
The underlying code paths are just too complex to hang our hat on any amount of time-bound code review. With that decision, we shifted our focus toward engineering efforts to validate the new library, identify edge cases, and limit the attack surface of our SAML code.
Validating the new library with A/B testing
GitHub.com processes around one million SAML payloads per business day, making it the most widely used form of external authentication that we support. Because this code is the front door for so many enterprise customers, any changes require a high degree of scrutiny and testing.
In order to preserve the stability of our SAML processing code while evaluating ruby-saml, we needed an abstraction that would give us the safety margins to experiment and iterate quickly.
There are several solutions for this type of problem, but at GitHub, we use a tool we have open sourced called Scientist. At its core, Scientist is a library that allows you to execute an experiment and compare two pieces of code: a control and a candidate. The result of the comparison is recorded so that you can monitor and debug differences between the two sources.
The beauty of Scientist is it always honors the result of the control, and isolates failures in your candidate, freeing you to truly experiment with your code in a safe way. This is useful for tasks like query performance optimization—or in our case, gaining confidence in and validating a new library.
Applying Scientist to SAML
GitHub supports configuring SAML against both organizations and enterprises. Each of these configurations is handled by a separate controller that implements support for SAML metadata, initiation of SAML authentication requests, and SAML response validation.
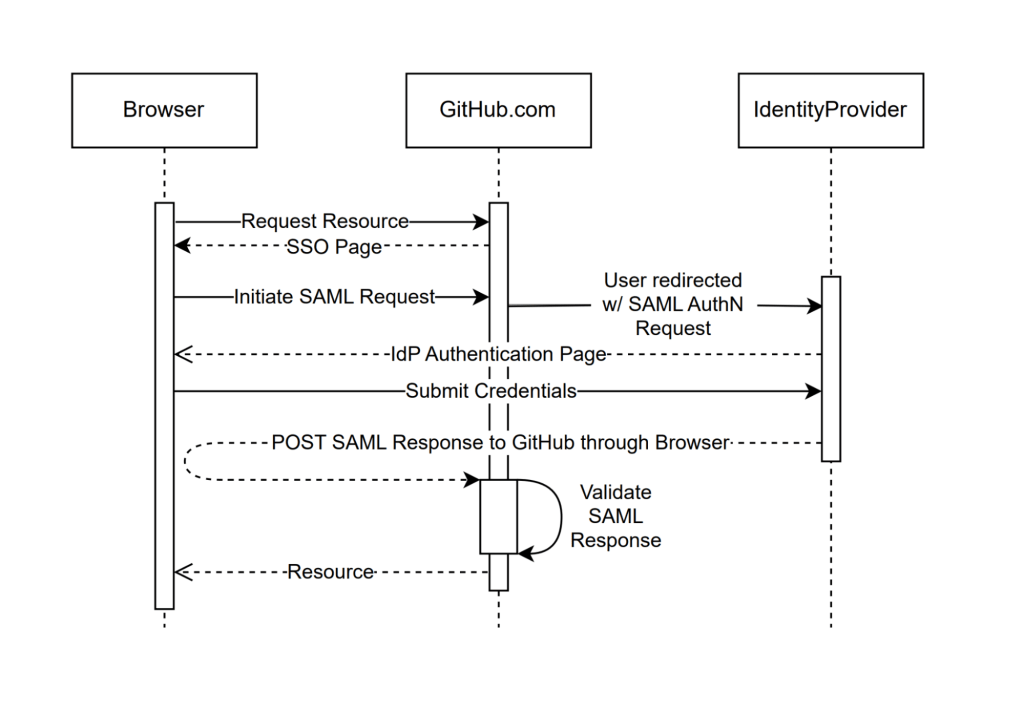
For the sake of building confidence, our primary focus was the code responsible for handling SAML response validation, also known as the Assertion Consumer Service (ACS) URL. This is the endpoint that does the heavy lifting to process the SAML response coming from the identity provider, represented in the SAML sequence diagram below as “Validate SAML Response.” Most importantly, this is where most vulnerabilities occur.
In order to gain confidence in ruby-saml, we needed to validate that we could get the library to handle our existing traffic correctly.
To accomplish this, we applied Scientist experiments to the controller code responsible for consuming the SAML response and worked on the following three critical capabilities:
Granular rollout gating: Scientist provides a percent-based control for enabling traffic on an experiment. Given the nature of this code path, we wanted an additional layer of feature flagging to ensure that we could send our own test accounts through the path before actual customer traffic
Observability: GitHub has custom instrumentation for experiments, which sends metrics to Datadog. We leaned heavily on this for monitoring our progress, but also added supplemental logging to generate more granular validation data to help debug differences between libraries.
Idempotency: There are pieces of state that are tracked during a SAML flow, such as tokens for CSRF, and we needed to ensure that our experiment did not modify them. Any changes must be clear of these code paths to prevent overwriting state.
When all was said and done, our experiment looked something like the following:
# gate the experiment by business, allowing us to run test account traffic through first
if business.feature_enabled?(:run_consume_experiment)
# auth_result is the result of `e.use` below
auth_result = science "consume_experiment" do |e|
# ensure that we isolate the raw response ahead of time, and scope the experiment to
# just the validation portion of response processing
e.use { consume_control_validation(raw_saml_response) }
e.try { consume_candidate_validation(raw_saml_response) }
# compare results and perform logging
e.compare { |control, candidate| compare_and_log_results(control, candidate) }
end
end
# deal with auth_result below...
So, how did our experiments help us build confidence in ruby-saml?
For starters, we used them to identify configuration differences between implementations. This guided our integration with the library, ensuring it could handle traffic in a way that was behaviorally consistent.
As an example, in September 2024 we noticed in our logs that approximately 3% of mismatches were caused by SAML issuer validation discrepancies. Searching the logs, we found that ruby-saml validated the issuer against an empty string. This helped us identify that some SAML configurations had an issuer set to an empty string, rather than null in the database.
Given that GitHub has not historically required an issuer for all SAML configurations, if the value is blank or unset, we skip issuer validation in our implementation. To handle this legacy invariant, we shipped a change that prevented configuring ruby-saml with blank or null issuer values, allowing the validation to be skipped in the library.
The impact of this change can be seen in graph below:
Once we set ruby-saml up correctly, our experiments allowed us to run all of our traffic through the library to observe how it would perform over an extended period of time. This was critical for building confidence that we had covered all edge cases. Most importantly, by identifying edge cases where the implementations handled certain inputs differently, we could investigate if any of these had security-relevant consequences.
By reviewing these exceptions, we were able to proactively identify incorrect behavior in either the new or old implementation. We also noticed during testing that ruby-saml rejected responses with multiple SAML assertions, while ours was more lenient.
While not completely wrong, we realized our implementation was trying to do too much. The information gained during this testing allowed us to safely augment our candidate code with new ideas and identify further areas of hardening like our next topic.
Schema validations and minimizing our attack surface
Before looking into stricter input validation, we first have to dive into what makes up the inputs we need to validate. Through our review of industry vulnerabilities, our implementation, and related research, we identified two critical factors that make parsing and validating this input particularly challenging:
The relationship between enveloped XML signatures and the document structure
The SAML schema flexibility
Enveloped XML Signatures
A key component of SAML is the XML signatures specification, which provides a way to sign and verify the integrity of SAML data. There are multiple ways to use XML signatures to sign data, but SAML relies primarily on enveloped XML signatures, where the signature itself is embedded within the element it covers.
Here’s an example of a <Response> element with an enveloped XML signature:
In order to verify this signature, we performed some version of the following high-level process:
Find the signature: Locate the <Signature> element in the <Response> element.
Extract values: Get the <SignatureValue> and <SignedInfo> from the <Signature>.
Extract reference and digest: From <SignedInfo>, extract the <Reference> (a pointer to the signed part of the document—note the URI attribute and the associated ID attribute on <Response>) and <DigestValue> (a hashed version of <Response>, minus the <Signature>).
Verify the digest: Apply the transformation instructions in the signature to the <Response> element and compare the results to the <DigestValue>.
Validate integrity: If the digest is valid, hash and encode <SignedInfo> using another algorithm, then use the configured public key (exchanged during SAML set up) to verify it against the <SignatureValue>.
If we get through this list of steps and the signature is valid, we assume that the <Response> element has not been tampered with. The interesting part about this is that to process the signature that legitimizes the <Response> element’s contents, we had to parse the <Response> element’s contents!
Put another way, the integrity of the SAML data is tied to its document structure, but that same document structure plays a critical role in how it is validated. Herein lies the crux of many SAML validation vulnerabilities.
This troubling relationship between structure and integrity can be exploited, and has been many times. One of the more common classes of vulnerability is the XML signature wrapping attack, which involves tricking the library into trusting the wrong data.
SAML libraries typically deal with this by querying the document and rejecting unexpected or ambiguous input shapes. This strategy isn’t ideal because it still requires trusting the document before verifying its authenticity, so any small blunders can be targeted.
Lax SAML schema definitions
SAML responses must be valid against the SAML 2.0 XML schema definition (XSD). XSD files are used to define the structure of XML, creating a contract between the sender and receiver about the sequence of elements, data types, and attributes.
This is exactly what we would look for in creating a clear set of inputs that we can easily limit parsing and validation around! Unfortunately, the SAML schema is quite flexible in what it allows, providing many opportunities for a document structure that would never appear in typical SAML responses.
For example, take a look at the SAML response below and notice the <StatusDetail> element. <StatusDetail> is one example in the spec that allows arbitrary data of any type and namespace to be added to the document. Consequently, including the elements <Foo>, <Bar>, and <Baz> into <StatusDetail> below would be completely valid given the SAML 2.0 schema.
Knowing that the signature verification process is sensitive to the document structure, this is problematic. These schema possibilities leave gaps that your code must check.
Consider an implementation that does not correctly associate signatures with signed data, only validating the first signature it finds because it assumes that the signature should always be in the <Response> element (which encompasses the <Assertion> element), or in the <Assertion> element directly. This is where the signatures are located in the schema, after all.
To exploit this, replace the contents of our previous example with a piece of correctly signed SAML data from the identity provider (remember that the schema allows any type of data in <StatusDetail>). Since the library only cares about the first signature it finds, it never verifies the <Assertion> signature in the example below, allowing an attacker to modify its contents to gain system access.
There are so manydifferent permutations of vulnerabilities like this that depend on the loose SAML schema, including many that we have protected against in our internal implementation.
Limiting the attack surface
While we can’t change how SAML works or the schema that defines it, what if we change the schema we validate it against? By making a stricter schema, we could enforce exactly the structure we expect to process, thereby reducing the likelihood of signature processing mistakes. Doing this would allow us to rule out bad data shapes before ever querying the document.
But in order to build a stricter schema, we first needed to confirm that the full SAML 2.0 schema wasn’t necessary. Our process began with bootstrapping: we gathered SAML responses from test accounts provided by our most widely integrated identity providers.
Starting small, we focused on Entra and Okta, which together accounted for nearly 85% of our SSO traffic volume. Using these responses, we crafted an initial schema based on real-world usage.
Next, we used Scientist to validate the schemas against our vast amount of production traffic. We first A/B tested with the very restrictive “bootstrapped” schema and gradually added back in the parts of the schema that we saw in anonymized traffic.
This allowed us to define a minimal schema that only contained the structures we saw in real-world requests. The same tooling we used for A/B testing allowed us to craft a minimal schema by iterating on the failures we saw across millions of requests.
How did the “strict” schema turn out based on our real-world validation from identity providers? Below are some of the key takeaways and schema restrictions we now enforce:
Ensure Signature elements are only where you expect them
We expect at most two elements to be signed: the Response, and the Assertion, but we know the schema is more lenient. For example, we don’t expect the SubjectConfirmationData or Advice elements to contain a signature, yet the following is a valid structure:
These are ambiguous situations that we can prevent. By removing <any> type elements, we can prevent additional signatures from being added to the document, and reduce the risk of attacks targeting flaws in signature selection logic.
It’s safe to enforce a single assertion in your response
The SAML spec allows for an unbounded number of assertions:
We expect exactly one assertion, and most SAML libraries account for this invariant by querying and rejecting documents with multiple assertions. By removing the minOccurs and maxOccurs attributes from the schema’s assertion choice, we can reject responses containing multiple assertions ahead of time.
This matters because multiple assertions in the document lead to structures that are vulnerable to XML signature wrapping attacks. Enforcing a single assertion removes structural ambiguity around the most important part of the document.
Remove additional elements and attributes that are unused in practice by your implementation
This is probably the least specific piece of advice, but important: Removing what you don’t support from the existing schema will reduce the risk of your application code handling that input incorrectly. For example, if you don’t support EncryptedAssertions, you should probably omit those definitions from your schema all together to prevent your code from touching data it doesn’t expect.
It is safe to reject document type definitions (DTDs)
While not strictly XSD related, we felt this was an important callout. DTDs are an older and more limited alternative to XSDs that add an unnecessary attack vector. Given that SAML 2.0 relies on schema definition files for validation, DTDs are both outdated and unnecessary, so we felt it best to disallow them altogether. In the wild, we never saw DTDs being used by identity providers.
The goal of a stricter SAML schema is to simplify working with SAML signatures and documents by removing ambiguity. By enforcing precise rules about where signatures should appear and their relationship to the data, validation becomes more straightforward and reliable.
While stricter schemas don’t eliminate all risks—since signature processing also depends on implementation—they significantly reduce the attack surface, enhancing overall security and minimizing the complex parsing we need to reason about for validation.
Limiting our vulnerability impact
At this point, we had made significant progress in addressing the risks associated with integrating ruby-saml and had restricted our critical inputs to a much smaller portion of the SAML schema.
By implementing safeguards, validating critical code paths, and taking a deliberate approach to testing, we mitigated many of the uncertainties inherent in adopting a new library and of SAML in general.
However, one fundamental truth remained: implementation vulnerabilities are inevitable, and we wanted to see what additional hardening we could apply to limit their impact.
Considering a compromise
Migrating to ruby-saml fully would mean embracing a more modern, actively maintained codebase that addresses known vulnerabilities. It would also position us for better long-term maintainability with broad community support: one of the primary motivators for this initiative.
However, replacing a core component like a SAML library isn’t without trade-offs. The risk of new vulnerabilities that weren’t surfaced during our work would always exist. With this in mind, we considered an alternative path: Instead of relying entirely on one library, why not use both?
We took this idea and ran with it by implementing a dual-parsing strategy and running both libraries independently and in parallel, requiring them to agree on validation before accepting a result. It might sound redundant and inefficient, but here’s why it worked to harden our implementation:
Defense in depth: The two libraries parse SAML differently. Exploiting both would require two independent vulnerabilities that work in unison—a much taller order than compromising just one.
Built-in feedback: When they disagree, we are notified. This gives us the opportunity to identify and investigate potential security critical edge cases. We can then feed stricter validation logic from one library back into the other.
No pressure to rush: Our original library is battle-tested and hardened. Using both together allows us to leverage its reliability while adopting the benefits of ruby-saml. We can always revisit this decision as we learn more about this strategy and its performance over time.
With this approach, we recognize that keeping something that works—when paired with something new—can be more powerful than replacing it outright. Of course, there are still risks involved. But by having two parsers, we increase our exposure of implementation vulnerabilities in our XML parsing code: things like memory corruption or XML external entity vulnerabilities. We also increase the burden of having to maintain two libraries.
Despite this, we decided that this risk and time investment is worth the increased resilience to the complex validation logic that is the core to the historical and critical vulnerabilities we’ve seen.
Learn from our blueprint
While our original goal was to “just” move to a new SAML library, we ended up taking the opportunity to reduce the risk profile of our entire SAML implementation.
By investing in upfront code review, security testing, and A/B testing and validation, we’ve gained confidence in the implementation of this new library. We then decreased the complexity of these code paths by restricting our allowed schema to one that is minimized using real world data. Finally, we’ve limited the impact of a single vulnerability found in either library by combining the strengths of both ruby-saml and our internal implementation.
As this code continues to parse almost a million SAML responses per day, our robust logging and exception handling will provide us with the observability needed to adjust our strategy or identify new hardening opportunities.
This experience should provide any team with a great blueprint on how to approach other complex or dangerous parts of a codebase they may be tasked with maintaining or hardening—and a reminder that incremental, data-driven experiments and compromises can sometimes lead to unexpected outcomes.
Critical authentication bypass vulnerabilities (CVE-2025-25291 + CVE-2025-25292) were discovered in ruby-saml up to version 1.17.0. Attackers who are in possession of a single valid signature that was created with the key used to validate SAML responses or assertions of the targeted organization can use it to construct SAML assertions themselves and are in turn able to log in as any user. In other words, it could be used for an account takeover attack. Users of ruby-saml should update to versi
Critical authentication bypass vulnerabilities (CVE-2025-25291 + CVE-2025-25292) were discovered in ruby-saml up to version 1.17.0. Attackers who are in possession of a single valid signature that was created with the key used to validate SAML responses or assertions of the targeted organization can use it to construct SAML assertions themselves and are in turn able to log in as any user. In other words, it could be used for an account takeover attack. Users of ruby-saml should update to version 1.18.0. References to libraries making use of ruby-saml (such as omniauth-saml) need also be updated to a version that reference a fixed version of ruby-saml.
In this blog post, we detail newly discovered authentication bypass vulnerabilities in the ruby-saml library used for single sign-on (SSO) via SAML on the service provider (application) side. GitHub doesn’t currently use ruby-saml for authentication, but began evaluating the use of the library with the intention of using an open source library for SAML authentication once more. This library is, however, used in other popular projects and products. We discovered an exploitable instance of this vulnerability in GitLab, and have notified their security team so they can take necessary actions to protect their users against potential attacks.
GitHub previously used the ruby-saml library up to 2014, but moved to our own SAML implementation due to missing features in ruby-saml at that time. Following bug bounty reports around vulnerabilities in our own implementation (such as CVE-2024-9487, related to encrypted assertions), GitHub recently decided to explore the use of ruby-saml again. Then in October 2024, a blockbuster vulnerability dropped: an authentication bypass in ruby-saml (CVE-2024-45409) by ahacker1. With tangible evidence of exploitable attack surface, GitHub’s switch to ruby-saml had to be evaluated more thoroughly now. As such, GitHub started a private bug bounty engagement to evaluate the security of the ruby-saml library. We gave selected bug bounty researchers access to GitHub test environments using ruby-saml for SAML authentication. In tandem, the GitHub Security Lab also reviewed the attack surface of the ruby-saml library.
As is not uncommon when multiple researchers are looking at the same code, both ahacker1, a participant in the GitHub bug bounty program, and I noticed the same thing during code review: ruby-saml was using two different XML parsers during the code path of signature verification. Namely, REXML and Nokogiri. While REXML is an XML parser implemented in pure Ruby, Nokogiri provides an easy-to-use wrapper API around different libraries like libxml2, libgumbo and Xerces (used for JRuby). Nokogiri supports parsing of XML and HTML. It looks like Nokogiri was added to ruby-saml to support canonicalization and potentially other things REXML didn’t support at that time.
We both inspected the same code path in the validate_signature of xml_security.rb and found that the signature element to be verified is first read via REXML, and then also with Nokogiri’s XML parser. So, if REXML and Nokogiri could be tricked into retrieving different signature elements for the same XPath query it might be possible to trick ruby-saml into verifying the wrong signature. It looked like there could be a potential authentication bypass due to a parser differential!
The reality was actually more complicated than this.
Roughly speaking, four stages were involved in the discovery of this authentication bypass:
Discovering that two different XML parsers are used during code review.
Establishing if and how a parser differential could be exploited.
Finding an actual parser differential for the parsers in use.
Leveraging the parser differential to create a full-blown exploit.
To prove the security impact of this vulnerability, it was necessary to complete all four stages and create a full-blown authentication bypass exploit.
Security assertion markup language (SAML) responses are used to transport information about a signed-in user from the identity provider (IdP) to the service provider (SP) in XML format. Often the only important information transported is a username or an email address. When the HTTP POST binding is used, the SAML response travels from the IdP to the SP via the browser of the end user. This makes it obvious why there has to be some sort of signature verification in play to prevent the user from tampering with the message.
Let’s have a quick look at what a simplified SAML response looks like:
Note: in the response above the XML namespaces were removed for better readability.
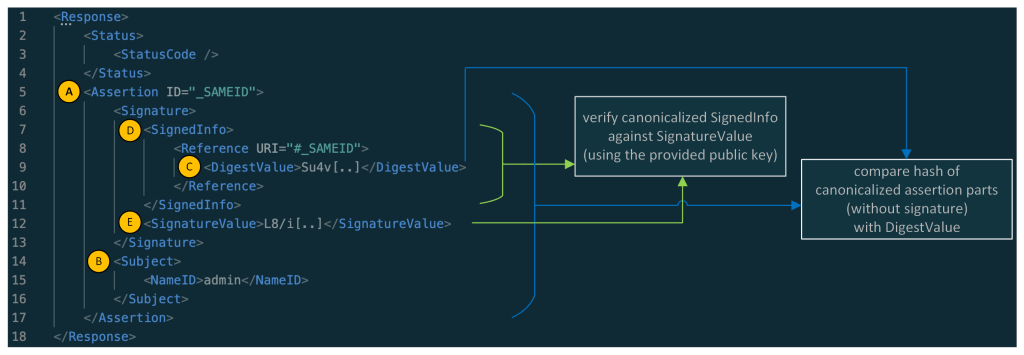
As you might have noticed: the main part of a simple SAML response is its assertion element (A), whereas the main information contained in the assertion is the information contained in the Subject element (B) (here the NameID containing the username: admin). A real assertion typically contains more information (e.g. NotBefore and NotOnOrAfter dates as part of a Conditions element.)
Normally, the Assertion (A) (without the whole Signature part) is canonicalized and then compared against the DigestValue (C) and the SignedInfo (D) is canonicalized and verified against the SignatureValue (E). In this sample, the assertion of the SAML response is signed, and in other cases the whole SAML response is signed.
We learned that ruby-saml used two different XML parsers (REXML and Nokogiri) for validating the SAML response. Now let’s have a look at the verification of the signature and the digest comparison.
The focus of the following explanation lies on the validate_signature method inside of xml_security.rb.
Inside that method, there’s a broad XPath query with REXML for the first signature element inside the SAML document:
Hint: When reading the code snippets, you can tell the difference between queries for REXML and Nokogiri by looking at how they are called. REXML methods are prefixed with REXML::, whereas Nokogiri methods are called on document.
Later, the actual SignatureValue is read from this element:
Note: the name of the Signature element might be a bit confusing. While it contains the actual signature in the SignatureValue node it also contains the part that is actually signed in the SignedInfo node. Most importantly the DigestValue element contains the digest (hash) of the assertion and information about the used key.
So, an actual Signature element could look like this (removed namespace information for better readability):
The method extract_signed_element_idextracts the signed element id with help of REXML. From the previous authentication bypass (CVE-2024-45409), there’s now a check that only one element with the same ID can exist.
The first of the reference_nodes is taken and canonicalized:
The assertion is extracted and canonicalized with Nokogiri, and then hashed. In contrast, the hash against which it will be compared is extracted with REXML.
The SignedInfo element is extracted and canonicalized with Nokogiri - it is then verified against the SignatureValue, which was extracted with REXML.
The question is: is it possible to create an XML document where REXML sees one signature and Nokogiri sees another?
It turns out, yes.
Ahacker1, participating in the bug bounty, was faster to produce a working exploit using a parser differential. Among other things, ahacker1 was inspired by the XML roundtrips vulnerabilities published by Mattermost’s Juho Forsén in 2021.
Not much later, I produced an exploit using a different parser differential with the help of Trail of Bits’ Ruby fuzzer called ruzzy.
Both exploits result in an authentication bypass. Meaning that an attacker, who is in possession of a single valid signature that was created with the key used to validate SAML responses or assertions of the targeted organization, can use it to construct assertions for any users which will be accepted by ruby-saml. Such a signature can either come from a signed assertion or response from another (unprivileged) user or in certain cases, it can even come from signed metadata of a SAML identity provider (which can be publicly accessible).
An exploit could look like this. Here, an additional Signature was added as part of the StatusDetail element that is only visible to Nokogiri:
In summary:
The SignedInfo element (A) from the signature that is visible to Nokogiri is canonicalized and verified against the SignatureValue (B) that was extracted from the signature seen by REXML.
The assertion is retrieved via Nokogiri by looking for its ID. This assertion is then canonicalized and hashed (C). The hash is then compared to the hash contained in the DigestValue (D). This DigestValue was retrieved via REXML. This DigestValue has no corresponding signature.
So, two things take place:
A valid SignedInfo with DigestValue is verified against a valid signature. (which checks out)
A fabricated canonicalized assertion is compared against its calculated digest. (which checks out as well)
This allows an attacker, who is in possession of a valid signed assertion for any (unprivileged) user, to fabricate assertions and as such impersonate any other user.
Parts of the currently known, undisclosed exploits can be stopped by checking for Nokogiri parsing errors on SAML responses. Sadly, those errors do not result in exceptions, but need to be checked on the errors member of the parsed document:
doc = Nokogiri::XML(xml) do |config|
config.options = Nokogiri::XML::ParseOptions::STRICT | Nokogiri::XML::ParseOptions::NONET
end
raise "XML errors when parsing: " + doc.errors.to_s if doc.errors.any?
While this is far from a perfect fix for the issues at hand, it renders at least one exploit infeasible.
We are not aware of any reliable indicators of compromise. While we’ve found a potential indicator of compromise, it only works in debug-like environments and to publish it, we would have to reveal too many details about how to implement a working exploit so we’ve decided that it’s better not to publish it. Instead, our best recommendation is to look for suspicious logins via SAML on the service provider side from IP addresses that do not align with the user’s expected location.
Some might say it’s hard to integrate systems with SAML. That might be true. However, it’s even harder to write implementations of SAML using XML signatures in a secure way. As others have stated before: it’s probably best to disregard the specifications, as following them doesn’t help build secure implementations.
To rehash how the validation works if the SAML assertion is signed, let’s have a look at the graphic below, depicting a simplified SAML response. The assertion, which transports the protected information, contains a signature. Confusing, right?
To complicate it even more: What is even signed here? The whole assertion? No!
What’s signed is the SignedInfo element and the SignedInfo element contains a DigestValue. This DigestValue is the hash of the canonicalized assertion with the signature element removed before the canonicalization. This two-stage verification process can lead to implementations that have a disconnect between the verification of the hash and the verification of the signature. This is the case for these Ruby-SAML parser differentials: while the hash and the signature check out on their own, they have no connection. The hash is actually a hash of the assertion, but the signature is a signature of a different SignedInfo element containing another hash. What you actually want is a direct connection between the hashed content, the hash, and the signature. (And once the verification is done you only want to retrieve information from the exact part that was actually verified.) Or, alternatively, use a less complicated standard to transport a cryptographically signed username between two systems - but here we are.
In this case, the library already extracted the SignedInfo and used it to verify the signature of its canonicalized string,canon_string. However, it did not use it to obtain the digest value. If the library had used the content of the already extracted SignedInfo to obtain the digest value, it would have been secure in this case even with two XML parsers in use.
As shown once again: relying on two different parsers in a security context can be tricky and error-prone. That being said: exploitability is not automatically guaranteed in such cases. As we have seen in this case, checking for Nokogiri errors could not have prevented the parser differential, but could have stopped at least one practical exploitation of it.
The initial fix for the authentication bypasses does not remove one of the XML parsers to prevent API compatibility problems. As noted, the more fundamental issue was the disconnect between verification of the hash and verification of the signature, which was exploitable via parser differentials. The removal of one of the XML parsers was already planned for other reasons, and will likely come as part of a major release in combination with additional improvements to strengthen the library. If your company relies on open source software for business-critical functionality, consider sponsoring them to help fund their future development and bug fix releases.
If you’re a user of ruby-saml library, make sure to update to the latest version, 1.18.0, containing fixes for CVE-2025-25291 and CVE-2025-25292. References to libraries making use of ruby-saml (such as omniauth-saml) need also be updated to a version that reference a fixed version of ruby-saml. We will publish a proof of concept exploit at a later date in the GitHub Security Lab repository.
Special thanks to Sixto Martín, maintainer of ruby-saml, and Jeff Guerra from the GitHub Bug Bounty program.
Special thanks also to ahacker1 for giving inputs to this blog post.
2024-11-04: Bug bounty report demonstrating an authentication bypass was reported against a GitHub test environment evaluating ruby-saml for SAML authentication.
2024-11-04: Work started to identify and test potential mitigations.
2024-11-12: A second authentication bypass was found by Peter that renders the planned mitigations for the first useless.
2024-11-13: Initial contact with Sixto Martín, maintainer of ruby-saml.
2024-11-14: Both parser differentials are reported to ruby-saml, the maintainer responds immediately.
2024-11-14: The work on potential patches by the maintainer and ahacker1 begins. (One of the initial ideas was to remove one of the XML parsers, but this was not feasible without breaking backwards compatibility).
2025-02-04: ahacker1 proposes a non-backwards compatible fix.
2025-02-06: ahacker1 also proposes a backwards compatible fix.
2025-02-12: The 90 days deadline of GitHub Security Lab advisories ends.
2025-02-16: The maintainer starts working on a fix with the idea to be backwards-compatible and easier to understand.
2025-02-17: Initial contact with GitLab to coordinate a release of their on-prem product with the release of the ruby-saml library.
2025-03-12: A fixed version of ruby-saml was released.