PhantomRPC: A new privilege escalation technique in Windows RPC
![]()
Intro
Windows Interprocess Communication (IPC) is one of the most complex technologies within the Windows operating system. At the core of this ecosystem is the Remote Procedure Call (RPC) mechanism, which can function as a standalone communication channel or as the underlying transport layer for more advanced interprocess communication technologies. Because of its complexity and widespread use, RPC has historically been a rich source of security issues. Over the years, researchers have identified numerous vulnerabilities in services that rely on RPC, ranging from local privilege escalation to full remote code execution.
In this research, I present a new vulnerability in the RPC architecture that enables a novel local privilege escalation technique likely in all Windows versions. This technique enables processes with impersonation privileges to elevate their permissions to SYSTEM level. Although this vulnerability differs fundamentally from the “Potato” exploit family, Microsoft has not issued a patch despite proper disclosure.
I will demonstrate five different exploitation paths that show how privileges can be escalated from various local or network service contexts to SYSTEM or high-privileged users. Some techniques rely on coercion, some require user interaction and some take advantage of background services. As this issue stems from an architectural weakness, the number of potential attack vectors is effectively unlimited; any new process or service that depends on RPC could introduce another possible escalation path. For this reason, I also outline a methodology for identifying such opportunities.
Finally, I examine possible detection strategies, as well as defensive approaches that can help mitigate such attacks.
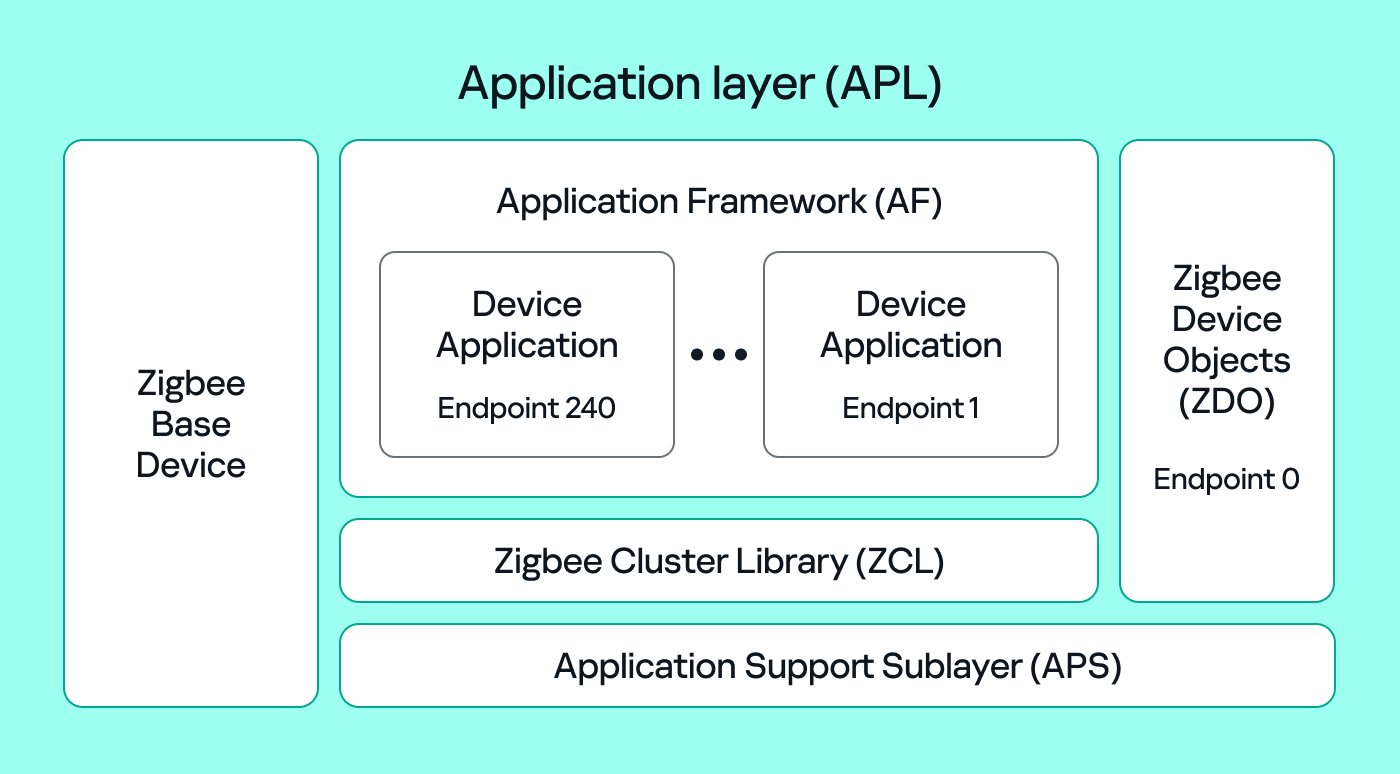
MSRPC
Microsoft RPC (Remote Procedure Call) is a Windows technology that enables communication between two processes. It enables one process to invoke functions that are implemented in another process, even though they are running in different execution contexts.
The figure below illustrates this mechanism.
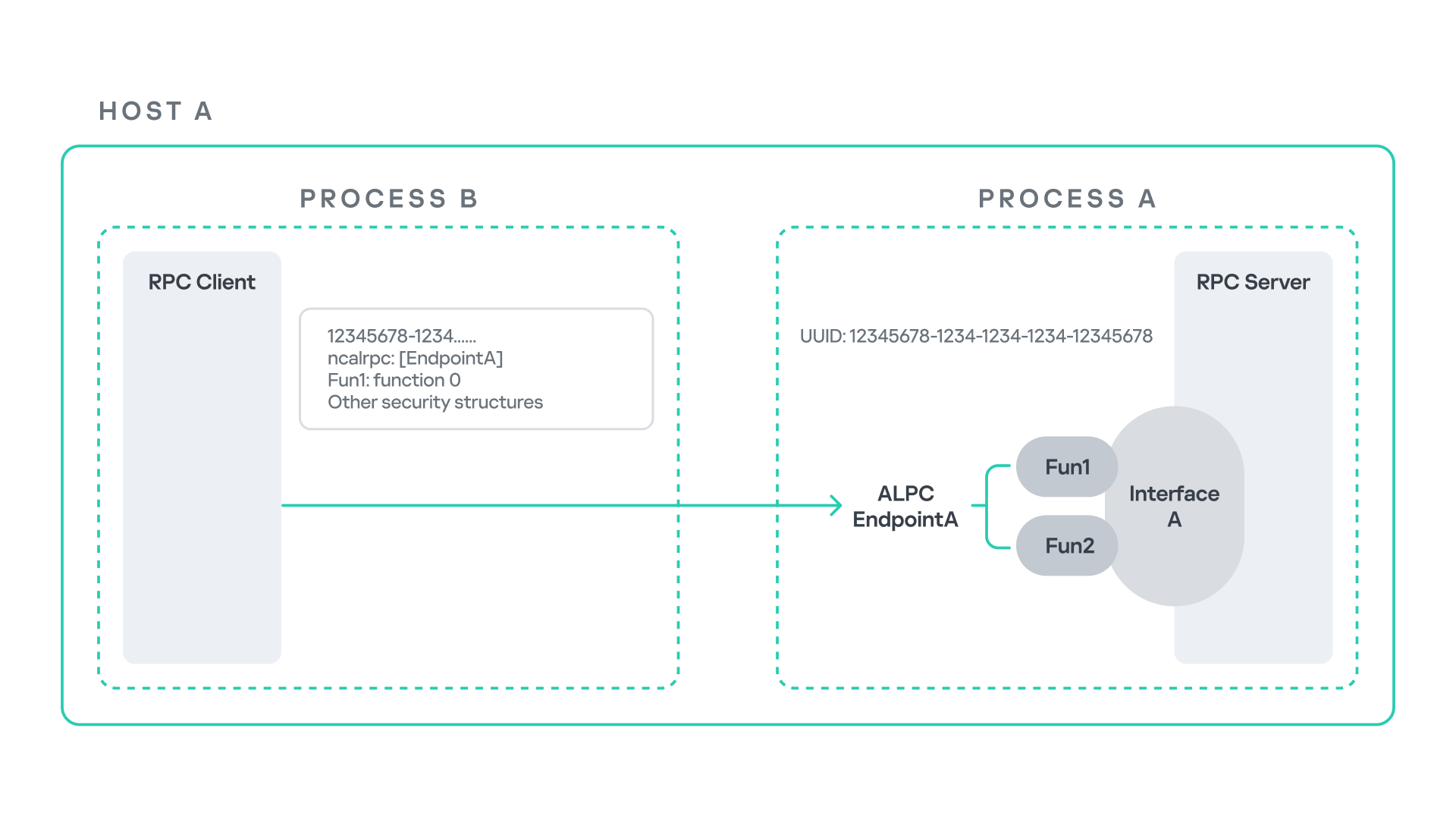
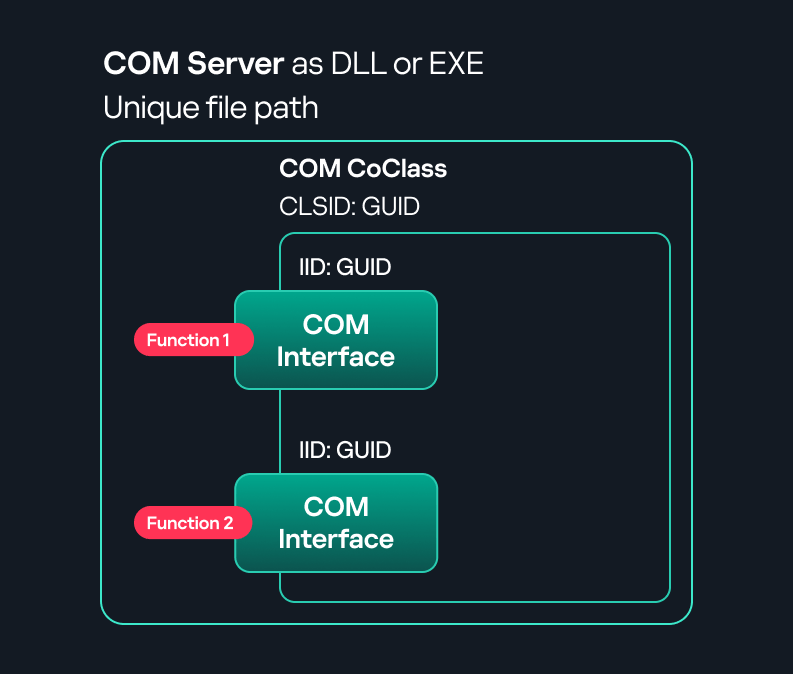
Let us assume that Host A is running two processes: Process A and Process B. Process B needs to execute a function that resides inside Process A. To enable this type of interaction, Windows provides the Remote Procedure Call (RPC) architecture, which follows a client–server model. In this model, Process A acts as the RPC server, exposing its functionality through an interface, in our example, Interface A. Each RPC interface is uniquely identified by a Universally Unique Identifier (UUID), which is represented as a 128-bit value. This identifier enables the operating system to distinguish one interface from another.
The interface defines a set of functions that can be invoked remotely by the RPC client implemented in Process B. In our example, the interface exposes two functions: Fun1 and Fun2.
To communicate with the server, the RPC client must establish a connection through a communication endpoint. An endpoint represents the access point that enables transport between the client and the server. Because RPC supports multiple transport mechanisms, different endpoint types may exist, depending on the underlying transport.
For example:
- When TCP is used as the transport layer, the endpoint is a TCP port.
- When SMB is used, communication occurs through a named pipe.
- When ALPC is used, the endpoint is an ALPC port.
Each transport mechanism is associated with a specific RPC protocol sequence. For instance:
ncacn_ip_tcpis used for RPC over TCP.ncacn_npis used for RPC over named pipes.ncalrpcis used for RPC over ALPC.
In this research, I focus specifically on Advanced Local Procedure Call (ALPC) as the RPC transport mechanism. ALPC is a Windows interprocess communication mechanism that predates MSRPC. Today, RPC can leverage ALPC as an efficient transport layer for communication between processes located on the same machine.
For simplicity, an ALPC port can be thought of as a communication channel similar to a file, where processes can send messages by writing to it, and receive messages by reading from it.
When the client wants to invoke a remote function, for example, Fun1, it must construct an RPC request. This request includes several important pieces of information, such as the interface UUID, the protocol sequence, the endpoint, and the function identifier. In RPC, functions are not referenced by name, but by a numerical identifier called the operation number (OPNUM). Depending on the requirements of the call, the request may also contain additional structures, such as security-related information.
Impersonation in Windows
In Windows, impersonation enables a service to temporarily operate using another user’s security context. For example, a service may need to open a file that belongs to a user while performing a specific operation. By impersonating the calling user, the system allows the service to access that file, even if the service itself would not normally have permission to do so. You can read more about impersonation in James Forshaw’s book Windows Security Internals.
This research focuses specifically on RPC impersonation. Instead of describing the interaction as a service and a user, I refer to the participants as a client and a server. In this model, the RPC server may temporarily adopt the identity of the client that initiated the request.
To perform this operation, the RPC server can call the RpcImpersonateClient API, which causes the server thread to execute under the client’s security context.
However, in some situations, a client may not want the server to be able to impersonate its identity. To control this behavior, Windows introduces the concept of an impersonation level. This defines how much authority the client grants the server to act on its behalf.
These settings are defined as part of the Security Quality of Service (SQOS) parameters, specified using the SECURITY_QUALITY_OF_SERVICE structure.
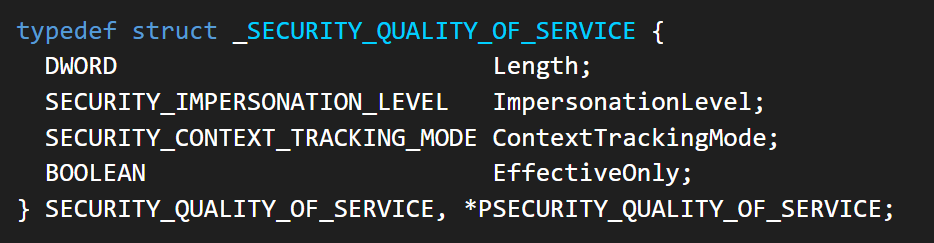
As you can see, this structure contains the impersonation level field, which determines the extent to which the server can assume the client’s identity.
Impersonation levels range from Anonymous, where the server cannot impersonate the client at all, to Impersonate and Delegate, which allow the server to act fully on behalf of the client.
At the same time, not every server process is allowed to impersonate a client. If any process could perform impersonation freely, it would pose a serious security risk. To prevent this, Windows requires the server process to possess a specific privilege called SeImpersonatePrivilege. Only processes with this privilege can successfully impersonate a client.
This privilege is granted by default to certain service accounts, such as Local Service and Network Service.
Interaction between Group Policy service and TermService
The Group Policy Client service (gpsvc) is a core Windows service responsible for applying and enforcing group policy settings on a system. It runs under the SYSTEM account inside svchost.exe.
When a group policy update is triggered, Windows uses an executable called gpupdate.exe. This tool can be executed with the /force flag to force an immediate refresh of all group policy settings. Internally, this executable communicates with the Group Policy service, which coordinates the update process.
At a certain stage during this operation, the Group Policy service attempts to communicate with TermService (Terminal Service, the Remote Desktop Services service) using RPC.
TermService is responsible for providing remote desktop functionality. This service is not running by default and can be enabled manually by the administrator via activation of Remote Desktop access. When this happens, the service exposes an RPC server with multiple interfaces and endpoints. TermService runs under the NT AUTHORITY\Network Service account.
When the command gpupdate /force is executed, the Group Policy service performs an RPC call to the TermService using the following parameters:
- UUID: bde95fdf-eee0-45de-9e12-e5a61cd0d4fe.
- Endpoint: ncalrpc:[TermSrvApi].
- Function: void Proc8(int).
However, because TermService is disabled by default, the RPC call fails and an exception occurs in rpcrt4.dll (the RPC runtime). The returned error is:
- 0x800706BA (RPC_S_SERVER_UNAVAILABLE, 1722).
This error indicates that the RPC client could not reach the target server.
Tracing the failure path further reveals that the root cause originates from a call to NtAlpcConnectPort, which is used by RPC to establish an ALPC connection between processes.
The NtAlpcConnectPort function is responsible for connecting to a specific ALPC port and returning a handle that the client can use for further communication. This function accepts multiple parameters.
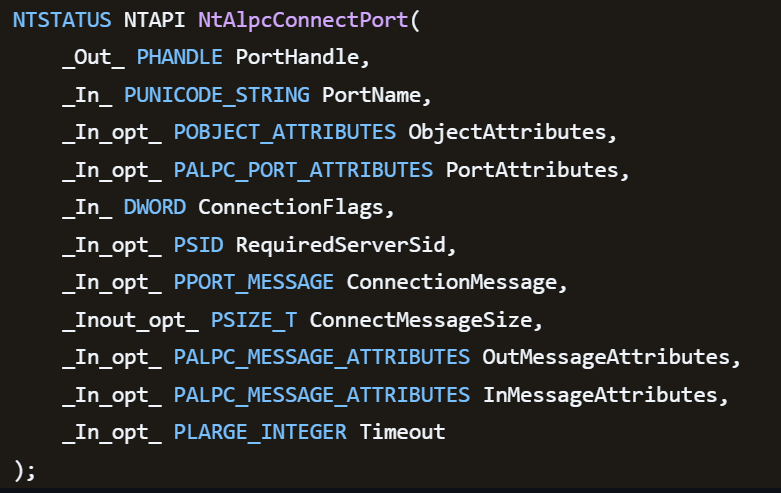
The first two parameters include:
- A pointer to the returned port handle.
- The ALPC port name, represented as an ASCII string.
Another important argument is PortAttributes, which is an ALPC_PORT_ATTRIBUTES structure. Inside this structure is the SECURITY_QUALITY_OF_SERVICE structure, which, as mentioned above, defines the impersonation level used for the connection.
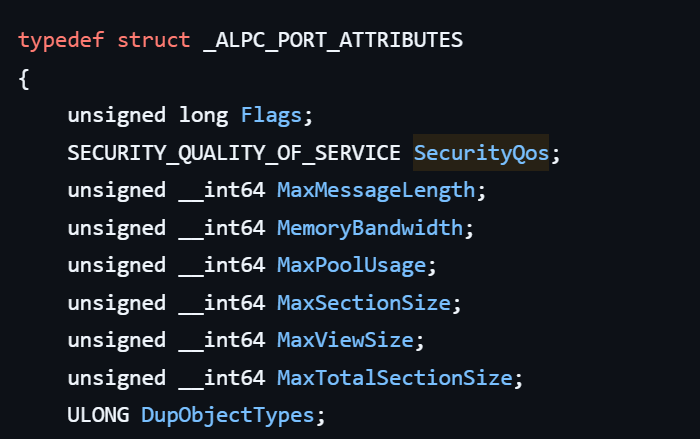
The final parameter of interest is RequiredServerSid, which specifies the expected identity of the target server process. This identity is represented using a Security Identifier (SID) structure.
Inspecting this call reveals that the Group Policy service attempts to connect to the RPC server using an impersonation level of Impersonate, expecting the remote server to run under the Network Service account. This behavior makes sense because TermService normally runs under Network Service.
Based on all the information above, the following scheme can be created to illustrate the interaction between TermService and gpsvc.
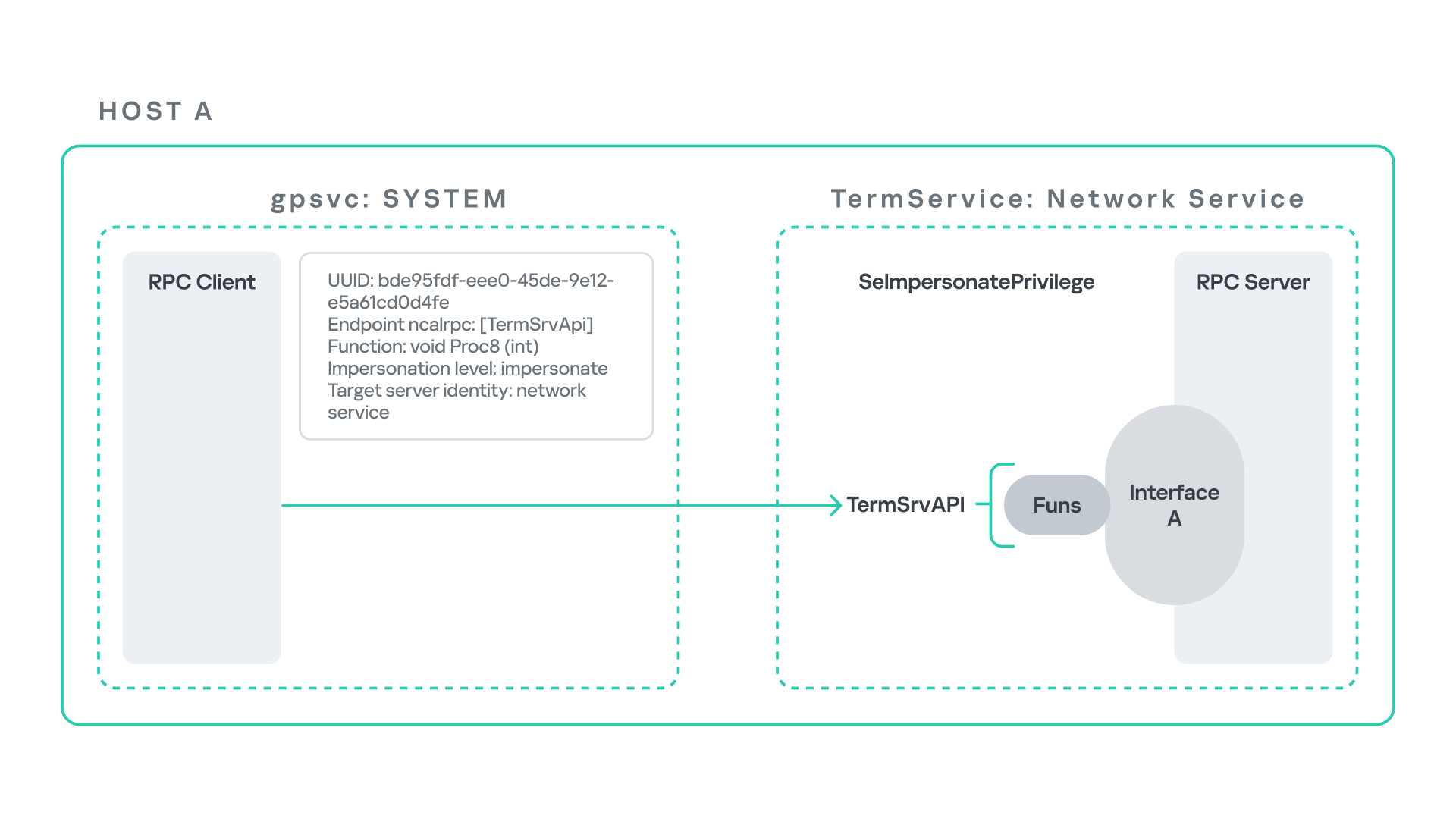
Up to this point, nothing unusual has occurred. An RPC client attempts to connect to an RPC server that is unavailable, resulting in an exception handled by the RPC runtime.
However, an interesting question arises: What if an attacker compromises a service that runs under the Network Service identity and mimics the exact RPC server exposed by TermService?
Could the attacker deploy a fake RPC server with the same endpoint?
If so, would the RPC runtime allow the client to connect to this illegitimate server?
And if the connection is successful, how could an attacker leverage this behavior?
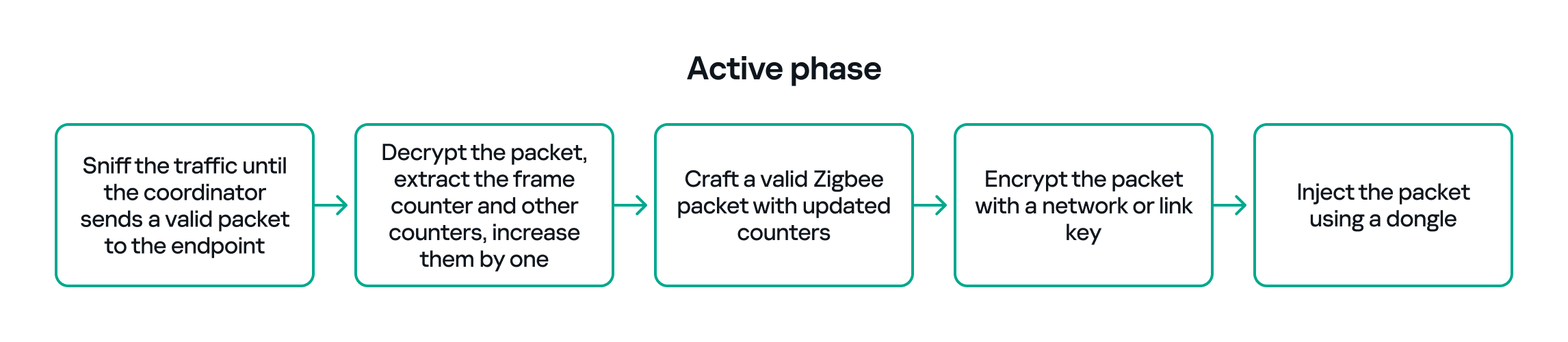
Coercing the Group Policy service
To better understand the implications of the previously described behavior, let us consider the following attack scenario.
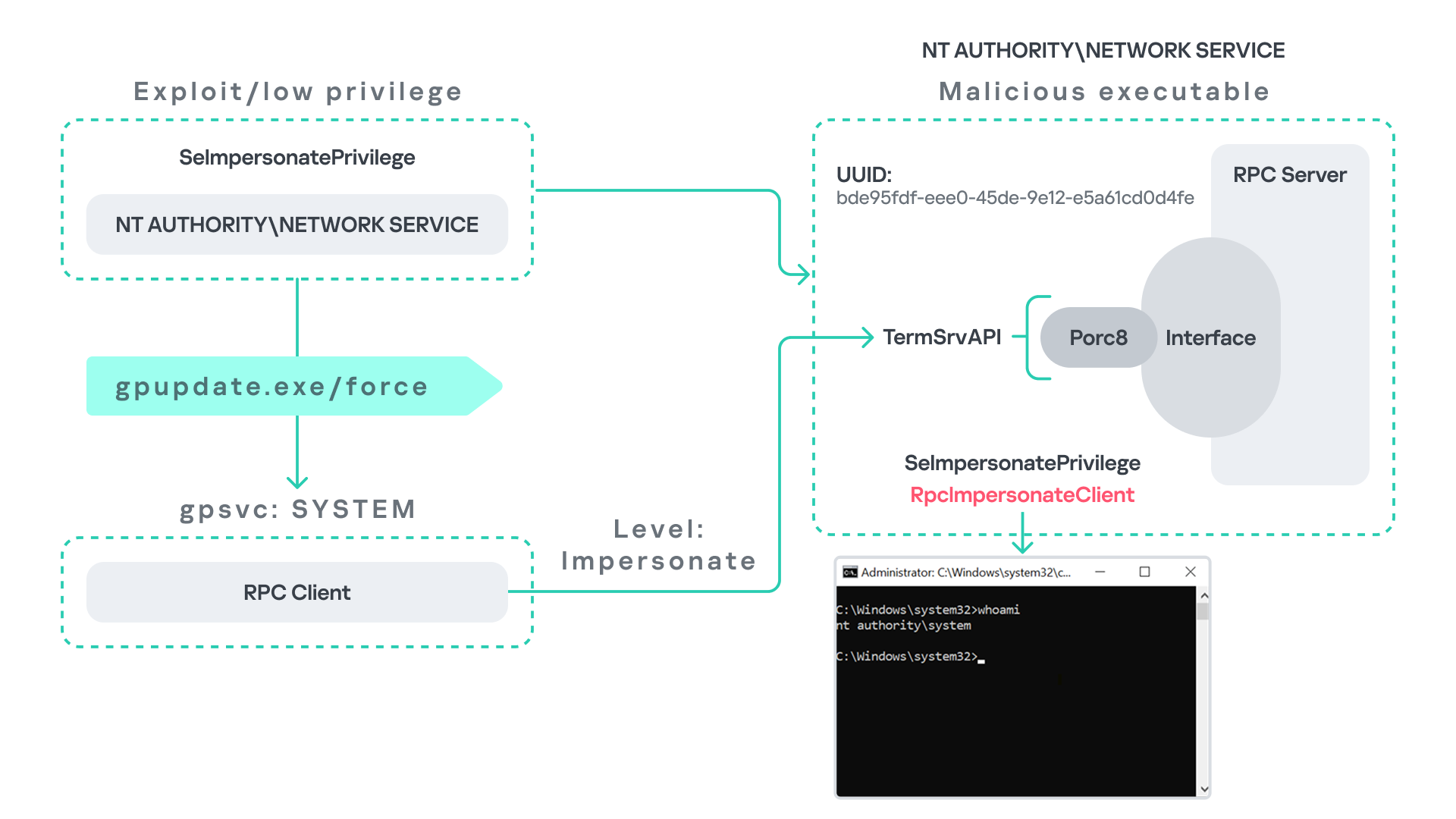
Imagine an attacker has compromised a service running on the system under the Network Service account, for example, an IIS server operating under the Network Service account. With this level of access, the attacker can deploy a malicious RPC server.
The attacker’s RPC server is designed to mimic the RPC interface exposed by the Remote Desktop service (TermService). Specifically, it implements the same RPC interface UUID and exposes the same endpoint name: TermSrvApi. Once deployed, the malicious server listens for RPC requests that would normally be directed to the legitimate RDP service.
Next, the attacker coerces the Group Policy service by triggering a policy update using gpupdate.exe /force. This causes the Group Policy Client service, which runs under the SYSTEM account, to perform the previously described RPC call. As observed earlier, this RPC call uses a high impersonation level (Impersonate).
When the attacker’s fake RPC server receives the request, it calls RpcImpersonateClient. This enables the server thread to impersonate the security context of the calling client, which, in this case, is SYSTEM.
As a result, the attacker can elevate privileges from Network Service to SYSTEM. In our proof-of-concept implementation, the exploit demonstrates privilege escalation by spawning a SYSTEM-level command prompt.
When this attack scenario was first discussed, it was purely theoretical. However, after implementing the malicious RPC server, the experiment confirmed that Windows allowed the server to be deployed and started successfully, and that the RPC runtime permitted the client to connect to the malicious endpoint. This made it possible to reliably escalate privileges from Network Service to SYSTEM using this technique. For this attack to succeed, though, at least one group policy must be applied on the system.
RPC architecture flow
Further investigation revealed that many Windows services attempt to communicate with TermService using RPC. These RPC calls often originate from winsta.dll, which acts as the RPC client component.
Windows processes invoke APIs exposed by winsta.dll; these APIs rely internally on RPC communication with TermService. This pattern is common in Windows; many system DLLs use RPC behind the scenes when their exported APIs are called.
However, it appears that the RPC runtime (rpcrt4.dll) does not provide a mechanism to verify the legitimacy of RPC servers. Moreover, Windows allows another process to deploy an RPC server that exposes the same endpoint as a legitimate service.
As a result, this architectural design introduces a large attack surface because RPC is heavily used across numerous system DLLs. Applications that invoke seemingly benign APIs may unintentionally trigger privileged RPC interactions. Under certain conditions, these interactions could be abused to achieve local privilege escalation without the user’s knowledge.
Identifying RPC calls to unavailable servers
As the issue appears to stem from an architectural weakness, a systematic approach is needed to identify RPC clients attempting to communicate with servers that are unavailable. First, I need a platform capable of monitoring RPC activity and extracting relevant information from each RPC request.
Specifically, I need to capture key RPC metadata, including:
- Interface UUID, endpoint, and OPNUM.
- Impersonation level and RPC status code.
- Client process privilege level, process name, and module path.
This information is critical because it enables me to reconstruct the RPC interaction, mimic the expected RPC server, and determine how the call is triggered.
The platform that provides this capability is Event Tracing for Windows (ETW). ETW is a built-in Windows logging framework that captures both kernel-mode and user-mode events in real time.
Windows provides a tool called logman to collect ETW data. It enables us to create trace sessions, select event providers, and configure the verbosity level of the tracing process. The collected tracing data is stored in an .etl file, which can later be analyzed using tools such as Event Viewer or other ETW analysis utilities.
ETW provides deep visibility into RPC activity without requiring modifications to applications. Through ETW, it is possible to capture detailed RPC information, such as:
- RPC bindings
- Endpoints
- Interface UUIDs
- Authentication details
- Call flow and timing
- RPC status codes
However, I’m not interested in every RPC event. My focus is on RPC call failures, specifically those that return the status RPC_S_SERVER_UNAVAILABLE.
For an event to be relevant to this research, the exception must meet two conditions:
- It must originate from a high-privileged process because impersonating such a process may allow an attacker to escalate privileges to a more powerful security context.
- The RPC call must use a high impersonation level, enabling the server to fully impersonate the client once the connection is established.
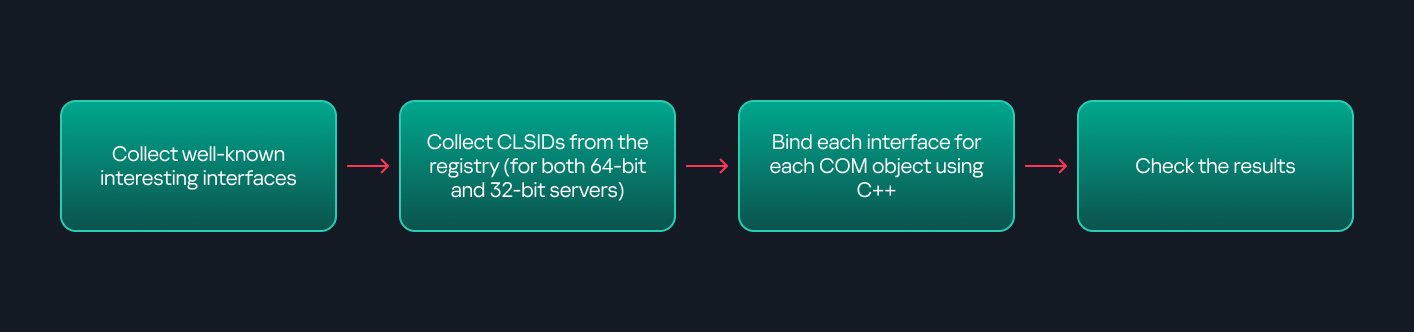
I cannot rely solely on the raw ETW output to implement this framework because it contains thousands of events, making manual filtering with standard tools inefficient. Therefore, I need to automate this process. The workflow shown below enables me to efficiently filter and extract only those events that are relevant to this analysis.
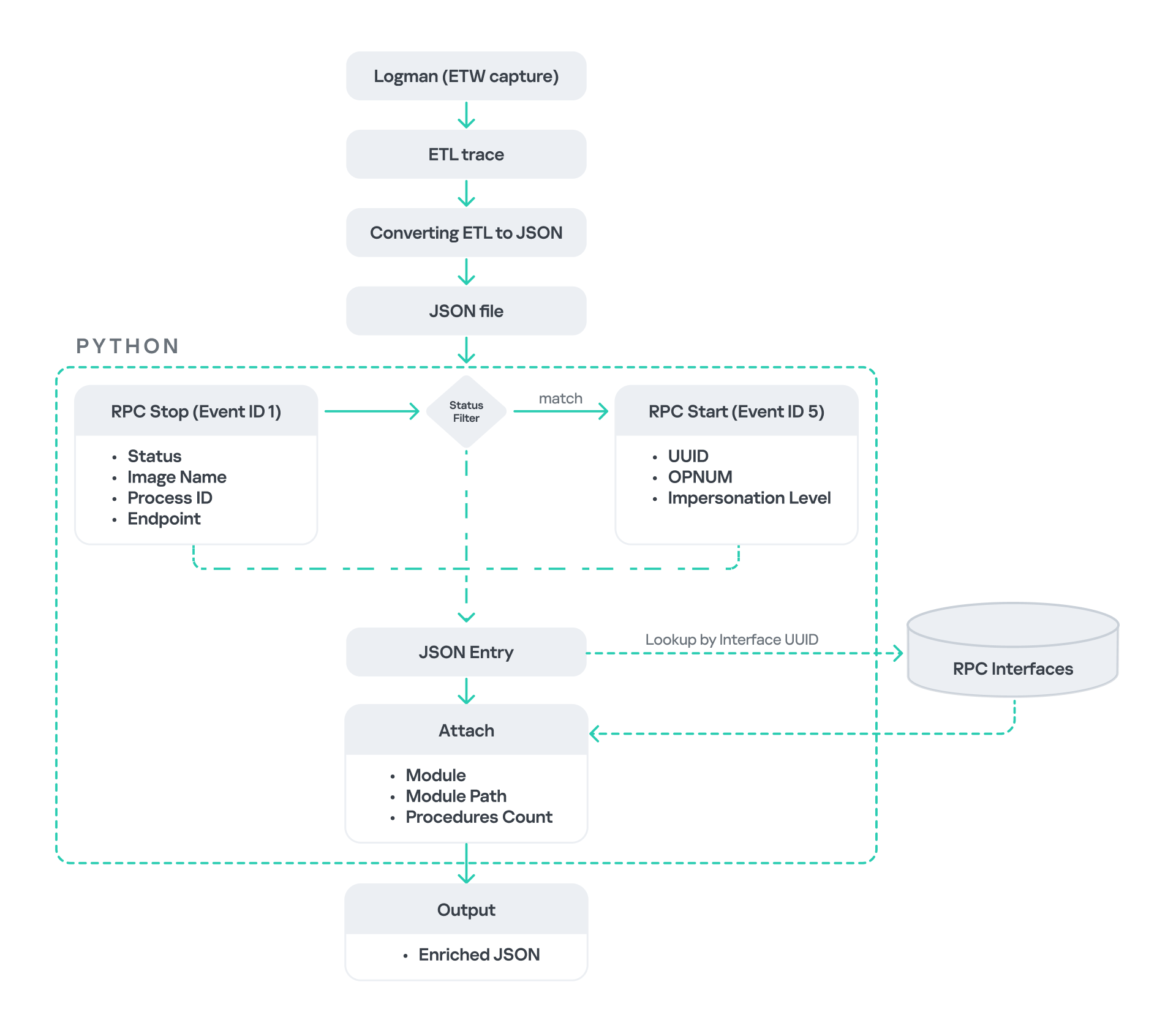
After generating the logs as an .etl file, I convert them to JSON format using tools such as etw2json. JSON is a much easier format to process programmatically. In this case, I use a Python script to filter and extract the relevant information.
The filtering process begins with a search for Event ID 1, which corresponds to an RPC stop event. This event indicates that the RPC client has completed the call and the result is available. From this event, I can extract useful information, such as:
- Status code
- Client process name
- Client process ID
- Endpoint
After extracting the status code, I filter for the specific value RPC_S_SERVER_UNAVAILABLE, which indicates that the target server was unreachable during an RPC call. These events represent the scenarios that are of interest.
However, Event ID 1 does not contain all of the required RPC metadata. To obtain the missing information, it is correlated with Event ID 5, which represents the RPC start event. This event is generated when the client initiates the RPC call.
By matching the metadata between Event ID 1 and Event ID 5, I can recover the missing details, including:
- Interface UUID
- OPNUM
- Impersonation level
After correlating and filtering these events, a JSON entry is obtained that is almost ready for analysis. At this stage, the data can be enriched further by adding context that will be helpful when reversing or analyzing the RPC server implementation. For example, the following can be identified:
- The DLL where the RPC interface is implemented
- The location of that DLL
- The number of procedures exposed by the interface
To retrieve this information, I match the UUID with an external RPC interface database. In this case, I used the RPC database, which contains a comprehensive list of RPC interfaces and their corresponding DLL implementations.
At the end of this process, a complete JSON dataset is obtained that can be used for further analysis.
One important observation is that the RPC calls I am looking for may only occur when specific system actions are triggered. Additionally, the resulting exceptions may vary from one system to another depending on which services are enabled or disabled. Therefore, I need a reliable way to generate these RPC exceptions.
In this research, I used several approaches to trigger such events:
- Monitoring RPC activity during system startup
I observed RPC activity while the system booted. During startup, many services initialize and perform various RPC calls, which increases the chances of capturing calls to unavailable servers. - Triggering administrative operations
I developed PowerShell scripts that perform common administrative tasks, such as updating Group Policy, changing network settings, or creating new users. These operations often trigger RPC communication and may generate exceptions. - Disabling services intentionally
After observing that Remote Desktop was disabled by default, I extended this idea by disabling additional services one by one and repeating the previous steps. This approach can reveal RPC clients that attempt to connect to services that are no longer available.
Additional privilege escalation paths
After running the logging and monitoring framework described earlier, I identified four additional scenarios that can lead to privilege escalation. The following sections introduce each case and explain how escalation can be achieved.
User interaction: From Edge to RDP
Microsoft Edge (msedge.exe) comes preinstalled on Windows systems. During startup, Edge triggers an RPC call to TermService. This RPC call is performed with a high impersonation level.
As previously discussed, Terminal Service is disabled by default. Because of this, the expected RPC server is unavailable, creating an opportunity for the attack scenario illustrated below.
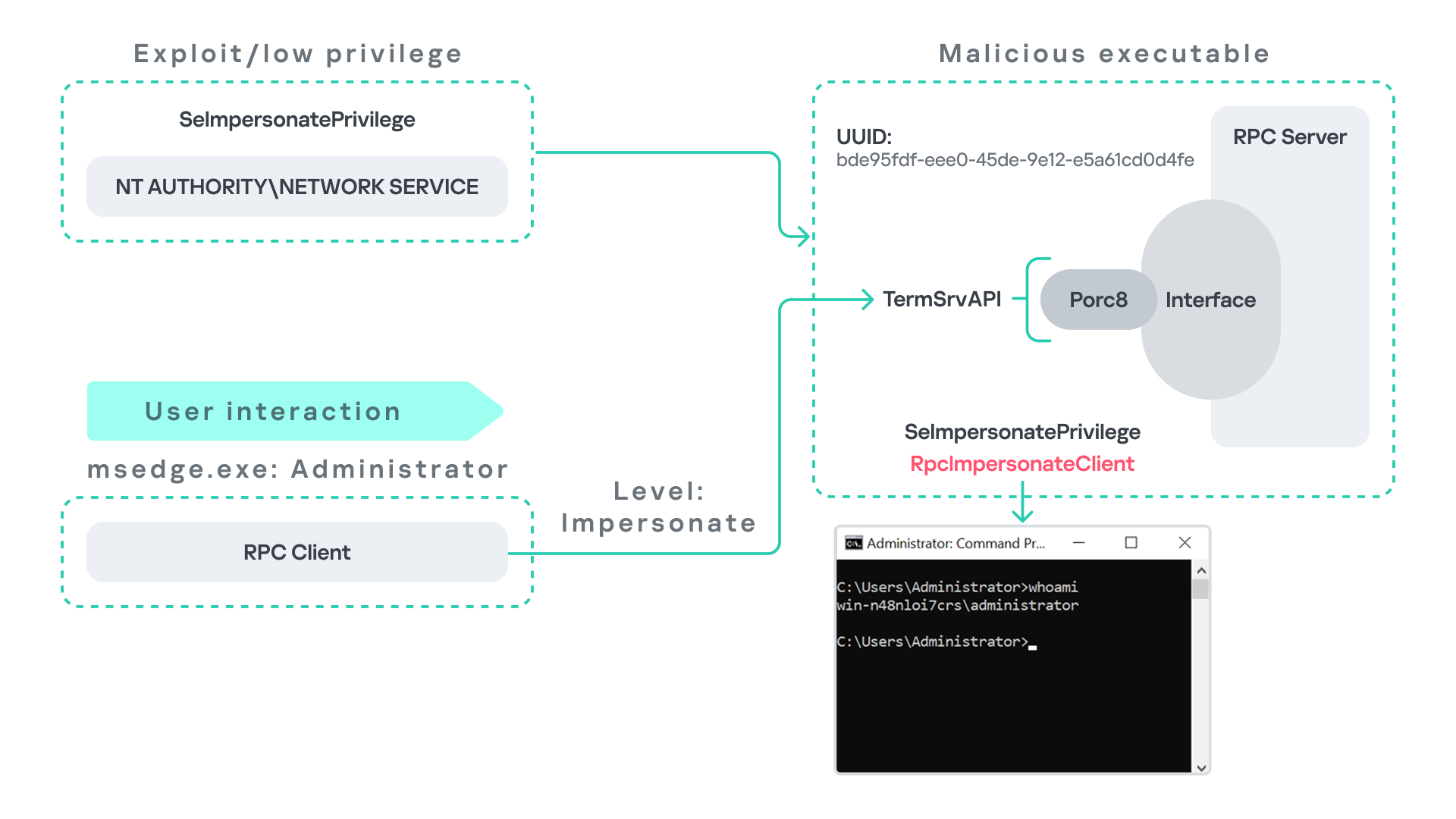
The attack follows the same initial assumption as before: the attacker has already compromised a process running under the Network Service account. From there, they deploy the same malicious RPC server that mimics the legitimate TermService RPC interface.
However, unlike the previous scenario where the attacker coerced the Group Policy service, no coercion is required this time. Instead, the attacker simply waits for a high-privileged user, such as an administrator, to launch msedge.exe.
When Edge starts, it triggers the RPC client to attempt communication with the expected TermService RPC interface. Because the legitimate server is not running, the request is received by the attacker’s fake RPC server. Since the RPC call is made with a high impersonation level, the malicious server can call RpcImpersonateClient to impersonate the client process.
As a result, the attacker is able to impersonate the administrator-level client and escalate privileges from Network Service to Administrator.
Background services: From WDI to RDP
Some background Windows services periodically attempt to make RPC calls to the RDP service without user interaction. One such service is the WdiSystemHost service. The Diagnostic System Host Service (WDI) is a built-in Windows service that runs system diagnostics and performs troubleshooting tasks. This service runs under the SYSTEM account.
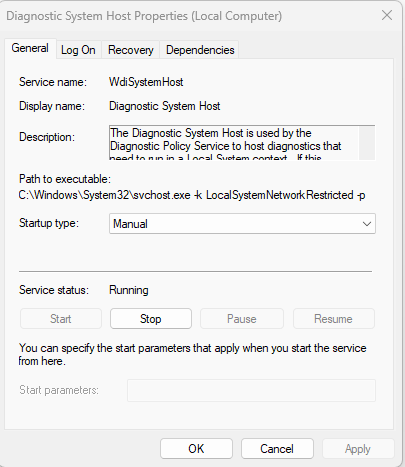
During normal operation, WDI periodically performs background RPC calls to the Remote Desktop service (TermService) using a high impersonation level. These RPC interactions occur automatically every 5–15 minutes and do not require any user input.
This behavior can be abused in a similar manner to the previous attack scenarios, as illustrated in the figure below.
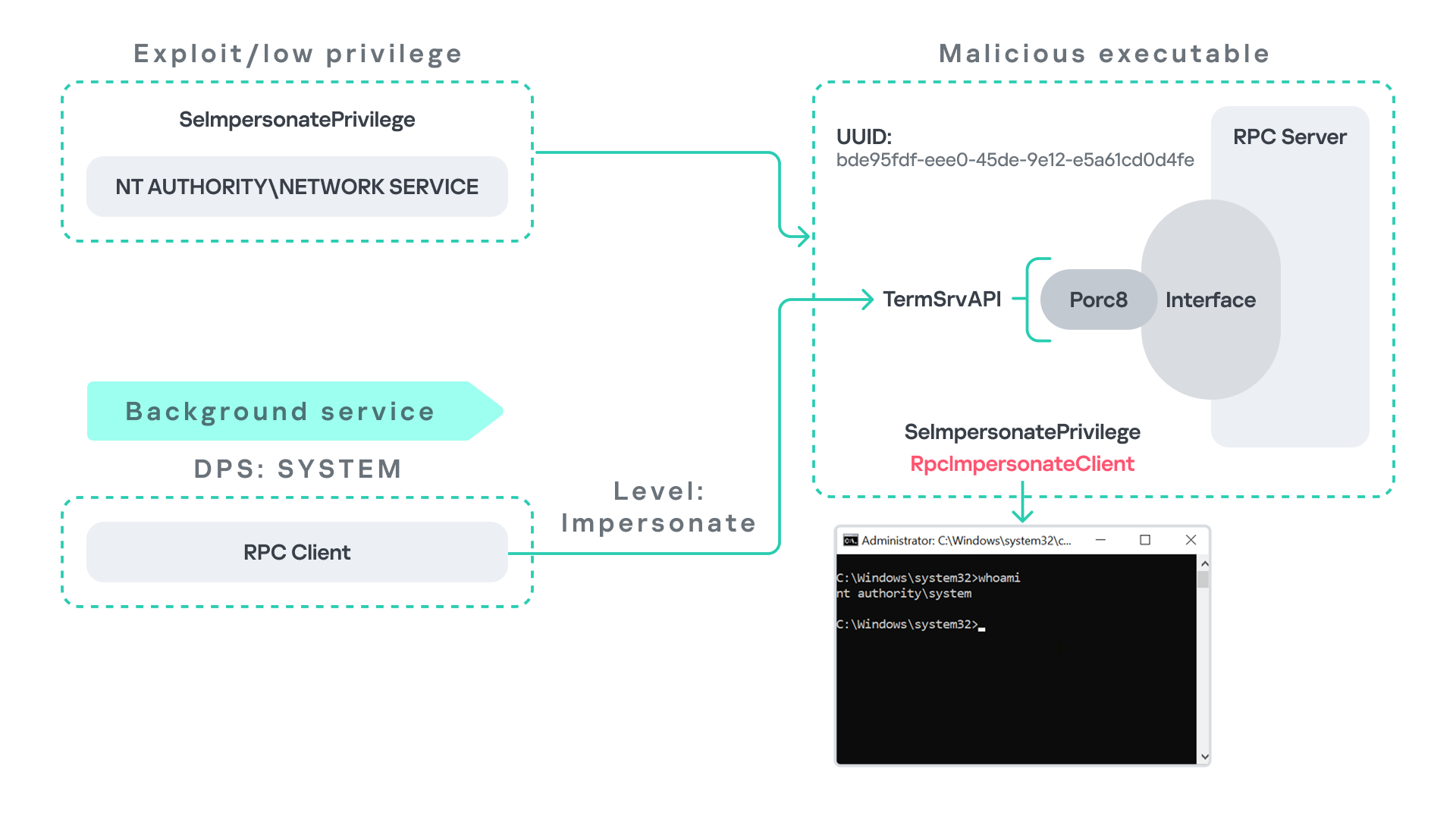
In this case, however, no user interaction or coercion is required. After deploying a malicious RPC server that mimics the expected TermService RPC interface, the attacker only needs to wait for the WDI service to perform its periodic RPC call. Because the request is made with a high impersonation level, the malicious server can invoke RpcImpersonateClient and impersonate the calling process. This enables the attacker to escalate privileges to SYSTEM.
Abusing the Local Service account: From ipconfig to DHCP
Another scenario involves the DHCP Client service, which manages DHCP client operations on Windows systems. This service runs under the Local Service account and is enabled by default.
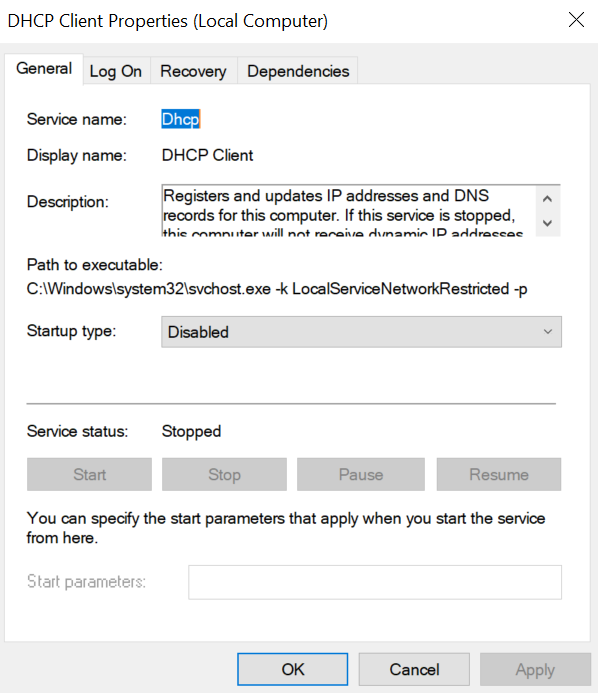
The DHCP Client service exposes an RPC server with multiple interfaces and endpoints. These interfaces are frequently invoked by various system DLLs, often using a high impersonation level.
In this scenario, instead of compromising a process running under Network Service, it is assumed the attacker has compromised a process running under the Local Service account. I also assume that the DHCP Client service is disabled, meaning the legitimate RPC server is unavailable.
As the figure below illustrates, the attacker can leverage this situation to escalate privileges.
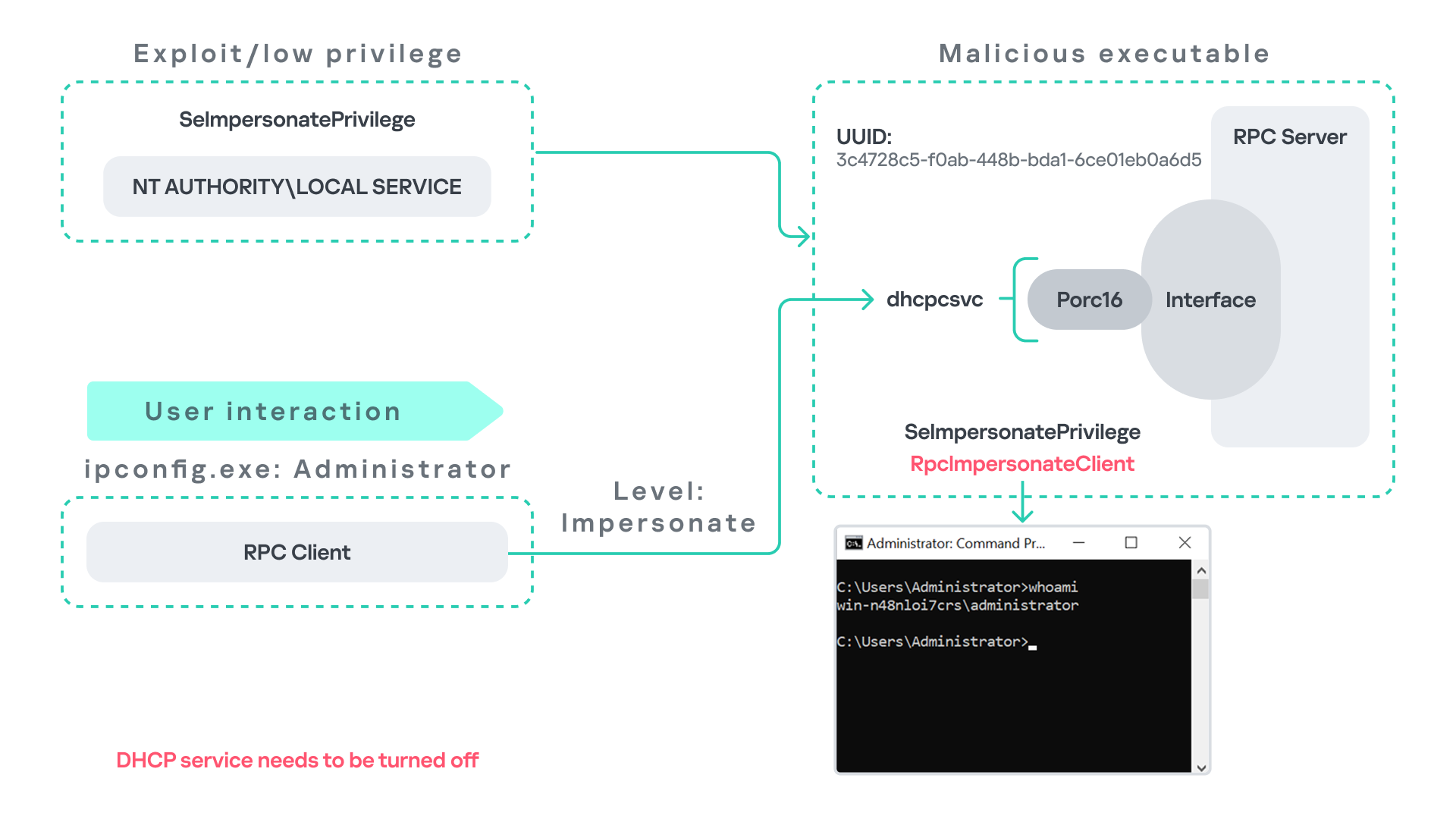
After gaining control of a Local Service process, the attacker deploys a malicious RPC server that mimics the legitimate RPC server normally exposed by the DHCP Client service. Once the malicious server is running, the attacker waits for a high-privileged user, such as an administrator, to execute ipconfig.exe.
When ipconfig is run, it internally triggers an RPC request to the DHCP Client service. Since the legitimate RPC server is not running, the request is received by the attacker’s fake RPC server. Because the RPC call is performed with a high impersonation level, the malicious server can call RpcImpersonateClient to impersonate the client.
As a result, the attacker can escalate privileges from the Local Service account to the Administrator account.
Abusing Time
The Windows Time service (W32Time) is responsible for maintaining date and time synchronization across systems in a Windows environment. This service is enabled by default and runs under the Local Service account.
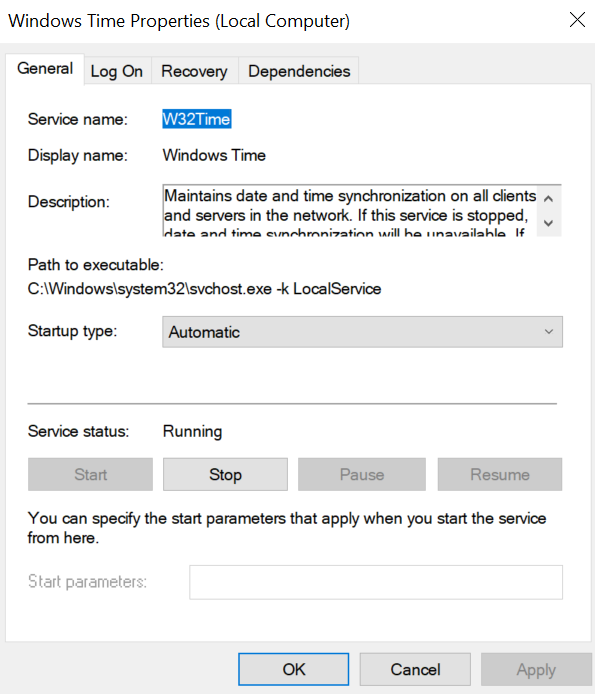
The service exposes an RPC server with two endpoints:
- \PIPE\W32TIME_ALT
- \RPC Control\W32TIME_ALT
The executable C:\Windows\System32\w32tm.exe interacts with the Windows Time service through RPC. However, before connecting to the valid RPC endpoints exposed by the service, the executable first attempts to access the nonexistent named pipe: \PIPE\W32TIME. This named pipe is not exposed by the legitimate W32Time service. However, if this endpoint were available, w32tm.exe would attempt to connect to it.
An attacker can abuse this behavior by deploying a malicious RPC server that mimics the legitimate RPC interface of the Windows Time service. Rather than exposing the legitimate endpoints, the attacker’s server exposes the nonexistent endpoint \PIPE\W32TIME, as shown in the figure below.
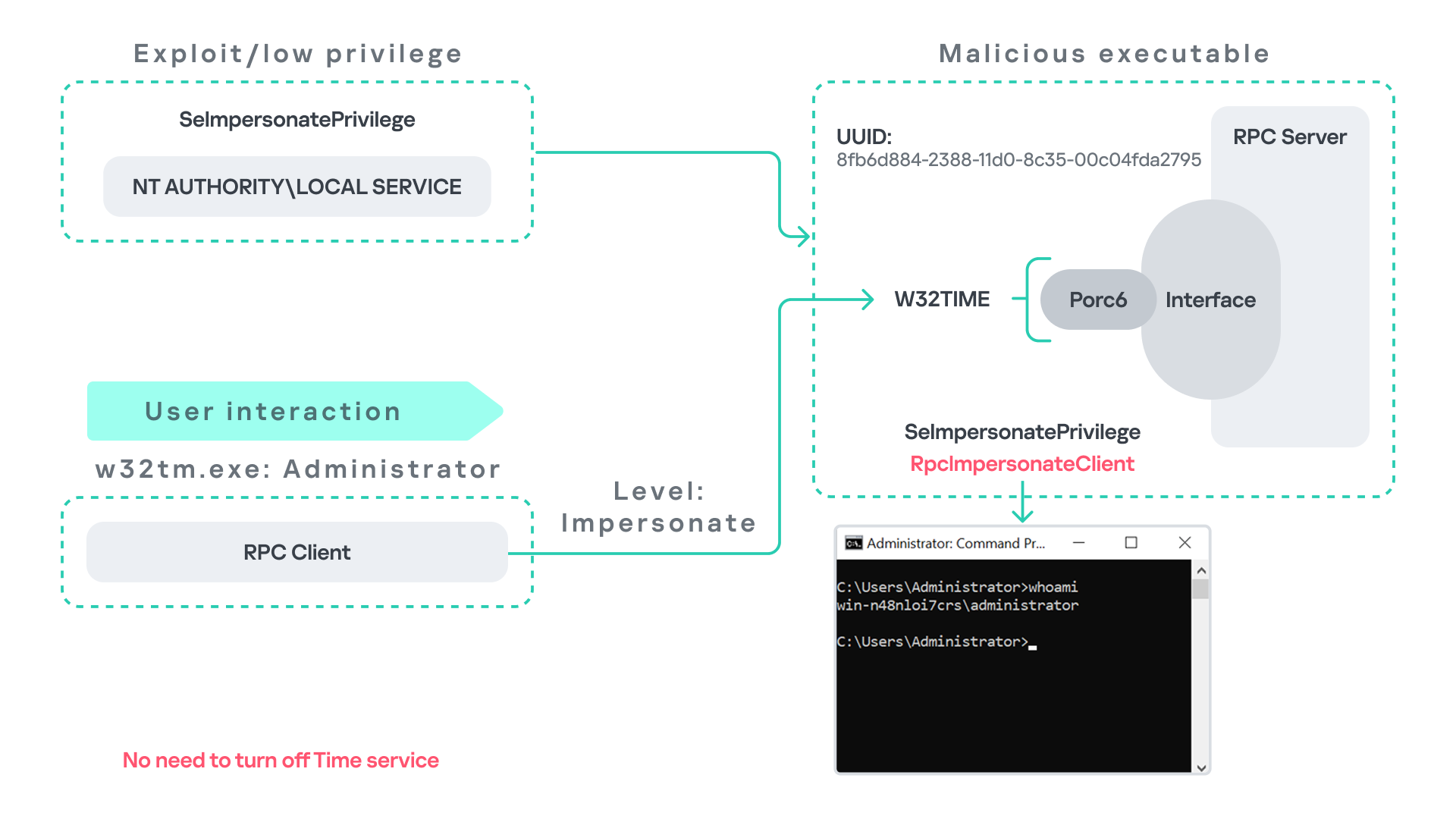
As in the previous scenarios, it is assumed the attacker has already compromised a process running under the Local Service account. The attacker then deploys a fake RPC server that implements the same RPC interface as the Windows Time service, but which exposes the alternative endpoint used by w32tm.exe.
Once the malicious server is running, the attacker simply waits for a high-privileged user, such as an administrator, to execute w32tm.exe. When the executable runs, it attempts to connect to the endpoint \PIPE\W32TIME. Because the attacker’s fake server exposes this endpoint, the RPC request is directed to the malicious server.
Since the RPC call is performed with a high impersonation level, the malicious server can impersonate the calling client. As a result, the attacker can escalate privileges from the Local Service account to the Administrator account.
In this scenario, it is important to note that the legitimate Windows Time service does not need to be disabled. Because the executable attempts to connect to a nonexistent endpoint, it is sufficient for the attacker to expose that endpoint through the malicious RPC server.
Vulnerability disclosure
After discovering the vulnerability, Kaspersky Security Services prepared a 10-page technical report describing the issue and the various aforementioned exploitation scenarios. The report was submitted to the Microsoft Security Response Center (MSRC) to report the vulnerability and request a fix.
Twenty days later, Microsoft responded, indicating that they did not classify the vulnerability as high severity. According to their assessment, the issue was classified as moderate severity and would therefore not be patched immediately. No CVE would be assigned, and the case would be closed without further tracking.
Microsoft explained that the moderate severity classification was due to the requirement that the originating process had to already possess the SeImpersonatePrivilege privilege. Since this privilege was typically required for the attack to succeed, Microsoft determined that the issue did not require immediate remediation.
Kaspersky Security Services respect Microsoft’s assessment and only published the research after the embargo period ends. In line with the coordinated vulnerability disclosure policy, Kaspersky Security Services will refrain from publishing detailed instructions that could enable or accelerate mass exploitation.
The disclosure timeline is shown below:
- 2025-09-19: Vulnerability reported to Microsoft Security Response Center (Case 101749).
- 2025-10-10: MSRC response – the case was assessed as moderate severity, not eligible for a bounty, no CVE was issued, and the case was closed without further tracking.
- 2026-04-24: expected whitepaper publication date.
Detection and defense
As discussed above, this vulnerability is related to an architectural design behavior. Fully preventing it would require Microsoft to release a patch that addresses the underlying issue.
Nevertheless, organizations can still take steps to detect and mitigate potential abuse. ETW-based monitoring within the framework described above enables defenders to identify RPC exceptions in their environment, especially when RPC clients attempt to connect to unavailable servers.
I have provide the tools used in the previously described framework so that organizations can check their environment for such behavior. You can find all of them in the research repository.
By monitoring these events, administrators can identify situations where legitimate RPC servers are expected but not running. In some cases, the attack surface may be reduced by enabling the corresponding services, ensuring that the legitimate RPC server is available. This can hinder attackers from deploying malicious RPC servers that imitate legitimate endpoints.
It is also good practice to reduce the use of the SeImpersonatePrivilege privilege in processes where it is not required. Some system processes need this privilege for normal operations. However, granting it to custom processes is generally not considered good security practice.
Conclusion
All the exploits described in this research were tested on Windows Server 2022 and Windows Server 2025 with the latest available updates prior to the submission date. The proof-of-concept implementations can be found in the research repository. However, it is highly likely that this issue may also be exploitable on other Windows versions.
Because the vulnerability stems from an architectural design issue, there may be additional attack scenarios beyond those presented in this research. The exact exploitation paths may vary from one system to another depending on factors such as installed software, the DLLs involved in RPC communication, and the availability of corresponding RPC servers.
![]()
![]()
![]()
![]()