A telemetry pipeline has become a core layer in modern security operations because teams no longer send data from applications, infrastructure, and cloud services straight into a single backend and hope for the best. In 2026, most environments are distributed across cloud, hybrid, and on-prem systems, which means more services, more data sources, more formats, and more operational complexity for teams that already struggle to keep visibility, control costs, and respond quickly.
Splunk’s State of Security 2025 found that 46% of security professionals spend more time maintaining tools than defending the organization. Cisco’s research adds that 59% deal with too many alerts, 55% face too many false positives, and 57% lose valuable investigation time because of gaps in data management. When too much raw telemetry flows into the stack without filtering, enrichment, or routing, the result is higher bills, slower investigations, and more noise for already stretched teams.
That is why telemetry pipelines are gaining momentum. They give organizations a control layer to normalize, enrich, route, and govern telemetry before it reaches SIEM, observability, or storage platforms. What began primarily as a way to control volume and cost is quickly becoming a must for modern security operations. Gartner suggests that by 2027, 40% of all log data will be processed through telemetry pipeline products, up from less than 20% in 2024.
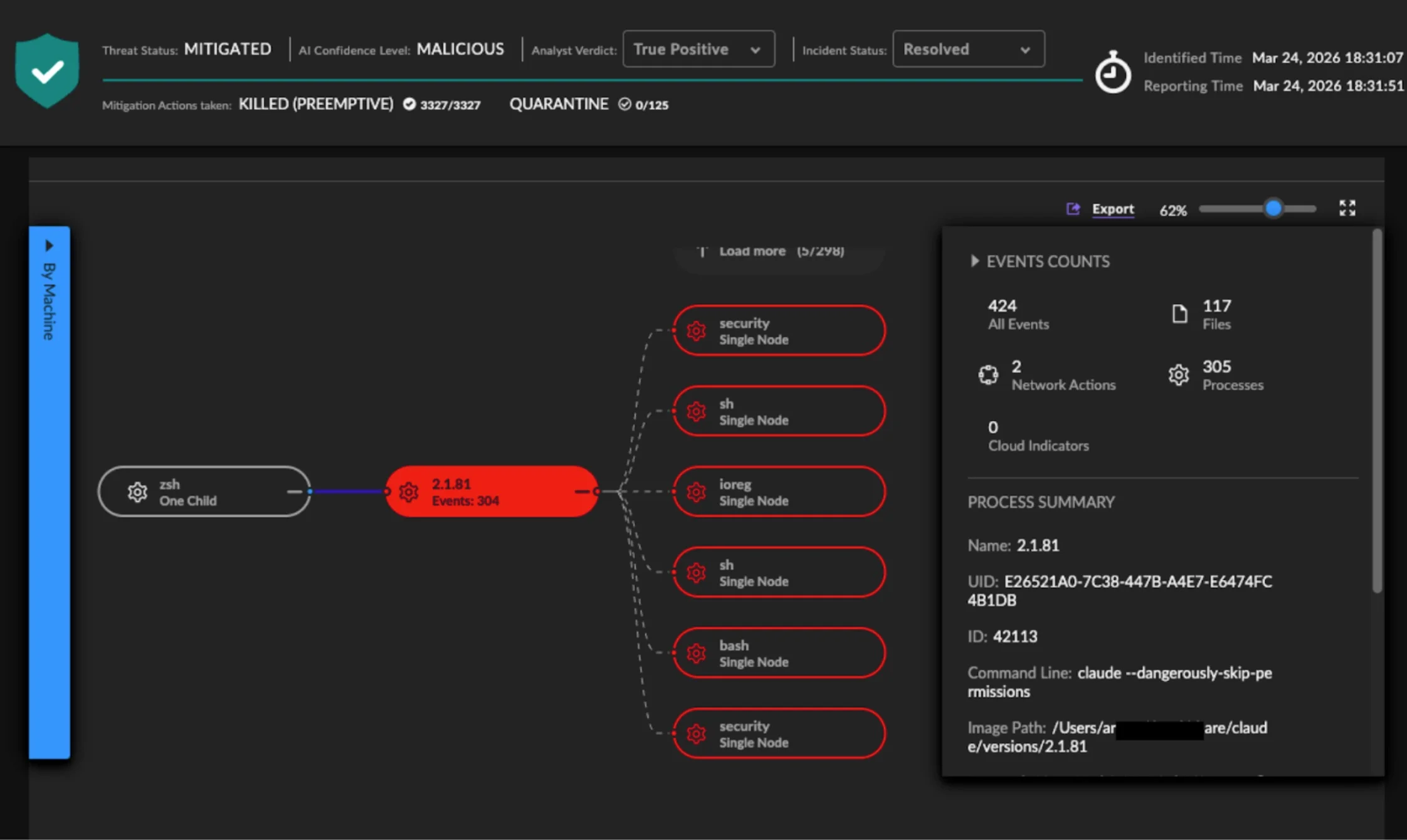
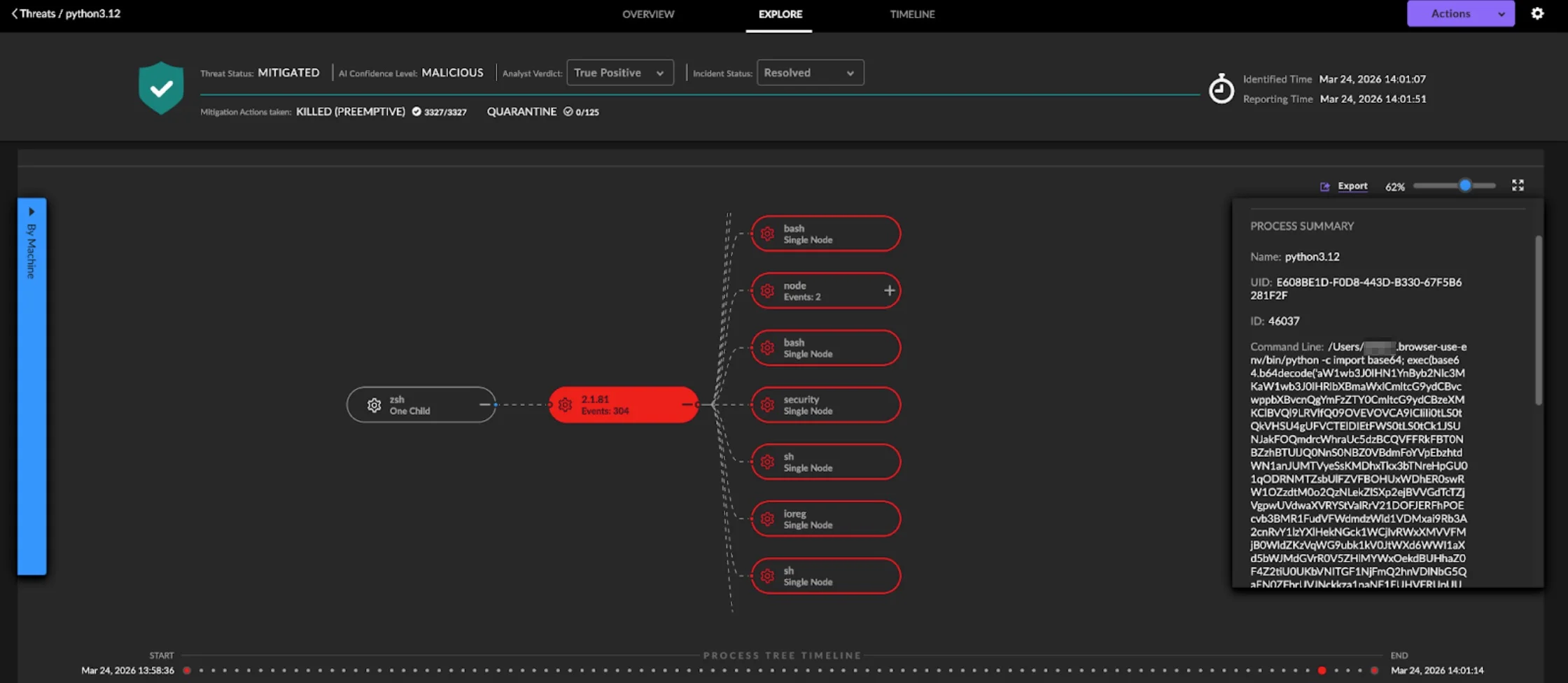
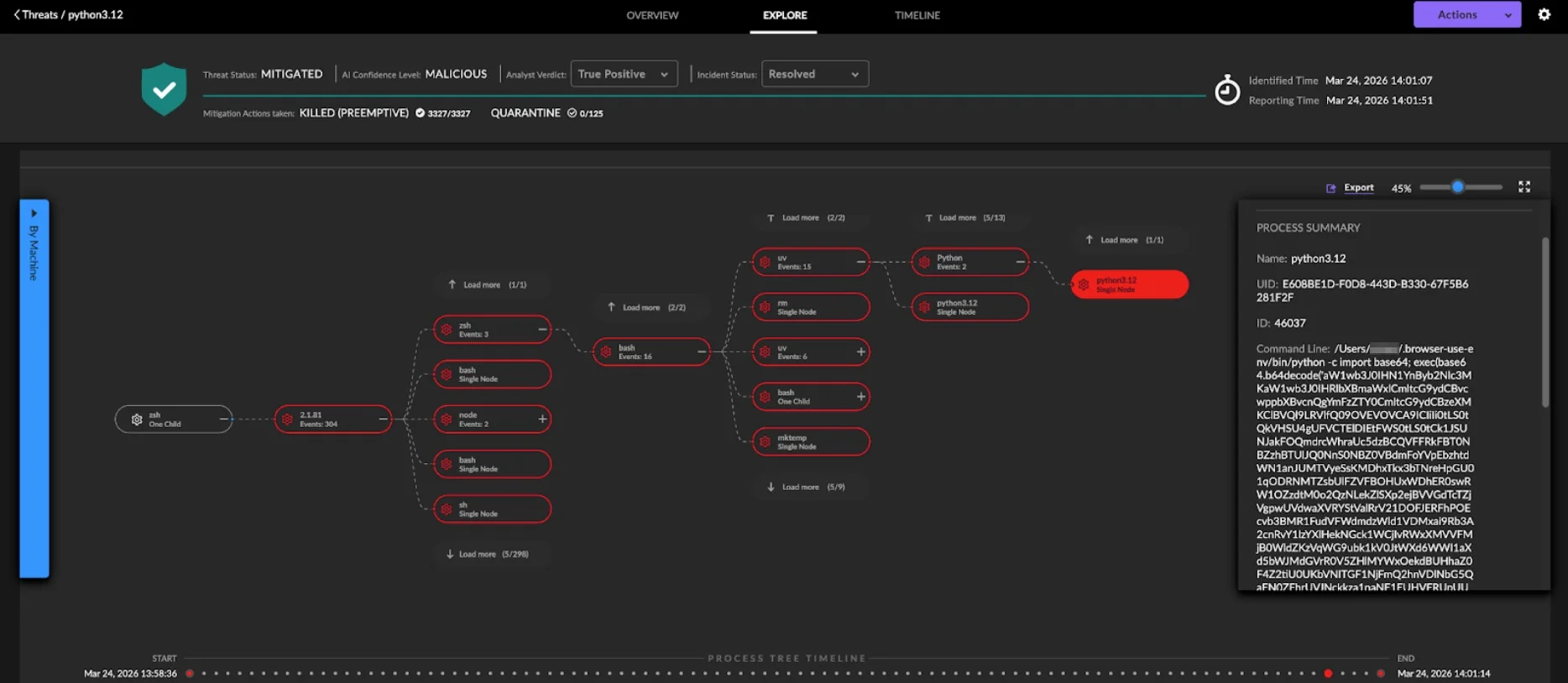
As that model matures, the next logical step is not just to manage telemetry better, but to make it useful earlier. If teams are already adding a pipeline to reduce noise, control spend, and improve routing, it makes sense to move part of the detection process closer to the stream itself rather than waiting for every event to land in downstream tools first. Solutions like SOC Prime’s DetectFlow act as an additional detection layer running directly on the stream. Instead of using the pipeline only for transport and optimization, DetectFlow applies tens of thousands of Sigma rules on live Kafka streams with Apache Flink, tags and enriches events in flight, and helps teams act on higher-value signals much earlier in the flow.
What Is Telemetry?
Before talking about telemetry pipelines, it is important to define telemetry itself.
Telemetry is the evidence systems leave behind while they run. It shows how applications, infrastructure, and services behave in real time, including performance, failures, usage, and health.
For enterprises, that evidence is valuable because it shows what users are actually experiencing, where bottlenecks form, when failures begin, and where suspicious activity starts to flicker. For security teams, telemetry is even more important because it becomes the raw material for detection, investigation, hunting, and response.
Put differently, telemetry is the trail of digital footprints your environment leaves behind. Useful on its own, but much more powerful when it is organized before the tracks disappear into the mud.
What Are the Main Types of Telemetry Data?
Most teams work with four main telemetry categories grouped under the MELT model: Metrics, Events, Logs, and Traces.
Metrics
Metrics are numerical measurements collected over time, such as CPU usage, memory consumption, latency, throughput, request volume, and error rate. They help teams track system health, identify trends, and spot anomalies before they become visible outages.
Events
Events capture notable actions or state changes inside a system. They usually mark something important that happened, such as a user login, a deployment, a configuration update, a purchase, or a failover. Events are especially useful because they often connect technical activity to business activity.
Logs
Logs are timestamped records of discrete activity inside an application, system, or service. They provide detailed evidence about what happened, when it happened, and often who or what triggered it. Logs are essential for debugging, troubleshooting, auditing, and security investigations.
Traces
Traces show the end-to-end path of a request as it moves across different services and components. They help teams understand how systems interact, how long each step takes, and where delays or failures occur. Traces are especially valuable in distributed systems and microservices environments.
Some platforms also break telemetry into more specific categories, such as requests, dependencies, exceptions, and availability signals. These help teams understand incoming operations, external service calls, failures, and uptime.
Telemetry Data Pros and Cons
Telemetry data can be one of the most valuable assets in modern operations, but only when it is managed with purpose. Done well, it gives teams a real-time view of how systems behave, how users interact with services, and where risks or inefficiencies begin to form. Done poorly, it becomes just another stream of noisy, expensive data.
Telemetry Data Benefits
The biggest advantage of telemetry is visibility. By collecting and analyzing metrics, logs, traces, and events, teams can see what is happening across applications, infrastructure, and services in real time.
Key benefits include:
- Real-time visibility into system health, performance, and user activity
- Proactive issue detection by spotting anomalies before they turn into outages or incidents
- Improved operational efficiency through automated monitoring and faster workflows
- Faster troubleshooting by giving teams the context needed to identify root causes quickly
- Better decision-making through data-backed insights for product, operations, and security teams
To get the full value, telemetry needs to be consolidated and handled consistently. A unified telemetry layer helps reduce mess across tools, improves scalability, and makes data easier to analyze and act on.
Telemetry Data Challenges
Telemetry also comes with real challenges, especially as data volumes grow. The most common ones include:
- Security and privacy risks when sensitive data is collected or stored without strong controls
- Legacy system integration across different formats, sources, and older technologies
- Rising storage and ingestion costs when too much low-value data is kept in expensive platforms
- Tool fragmentation makes correlation and investigation harder
- Interoperability issues when systems do not follow consistent standards or schemas
This is exactly why telemetry strategy matters. The goal is not to collect more data for the sake of it, but to collect the right data, shape it early, and route it where it creates the most value. In cybersecurity, that difference is critical. The right telemetry can speed up detection and response, while unmanaged telemetry can bury important signals under cost and noise.
How to Analyze Telemetry Data
The best way to analyze telemetry data is to stop treating analysis as the last step. In practice, good analysis starts much earlier, with clear goals, structured collection, smart routing, and storage policies that keep useful data accessible without flooding downstream tools.
Define Goals
Start with the question behind the data. Are you trying to improve performance, reduce MTTR, monitor customer experience, detect security threats, or control SIEM costs? Once that is clear, decide which signals matter most and which KPIs will show progress. For a product team, that may be latency and error rate. For a SOC, it may be detection coverage, false positives, and investigation speed. This is also the stage to set privacy and compliance boundaries so teams know what data should be collected, masked, or excluded from the start.
Configure Collection
Once goals are clear, configure the tools that will collect the right telemetry from the right places. That usually means deciding which applications, hosts, cloud services, APIs, endpoints, and identity systems should send logs, metrics, traces, and events. It also means setting practical rules for sampling, field selection, filtering, and schema consistency.
Shape and Route the Data
Before data reaches SIEM, observability, or storage platforms, it should be shaped to fit the goal. That can mean normalizing records into consistent schemas, enriching events with identity or asset context, filtering noisy data, redacting sensitive fields, and routing each signal to the destination where it creates the most value.
Store Data With Intent
Not all telemetry needs the same retention period, storage tier, or query speed. High-value operational and security data may need to stay hot for rapid search and alerting, while bulk historical data can move to cheaper long-term storage. The key is to align retention with investigation needs, compliance obligations, and cost tolerance.
Analyze, Alert, and Refine
Only after that foundation is in place does analysis become truly useful. Dashboards, alerts, anomaly detection, and visualizations work much better when the underlying telemetry is already clean, consistent, and routed with purpose. Machine learning and AI can make this process more effective by helping teams spot unusual patterns, detect anomalies faster, and identify changes that may be easy to miss in high-volume environments.
That is especially important in security operations, where the real challenge is turning telemetry into better decisions with less noise. This is exactly why a pipeline-based approach becomes so valuable. When telemetry is already being normalized, enriched, and routed upstream, analysis can start earlier, before raw events pile up in costly SIEM platforms.
Solutions like DetectFlow placе detection logic, threat correlation, and Agentic AI capabilities directly in the pipeline. At the pre-SIEM stage, DetectFlow can correlate events across log sources from multiple systems, while Flink Agent and AI help surface the attack chains that matter in real time and reduce false positives. In practice, that means teams can move detection left and deliver cleaner, richer, and more actionable signals downstream.
Telemetry and Monitoring: Main Difference
Telemetry and monitoring are closely related, but they are not the same thing. Telemetry is the process of collecting and transmitting data from systems and applications. It captures raw signals such as metrics, logs, traces, and events, then sends them to a central place for analysis. Monitoring is what teams do with that data to understand system health, performance, and availability. It turns telemetry into dashboards, alerts, and reports that help people act on what they see.
The difference matters because many organizations still build their strategy around dashboards and alerts alone. Monitoring is important, but it is only one use of telemetry. Security teams also rely on telemetry for investigation, hunting, root-cause analysis, and detection engineering. In other words, telemetry is the foundation, while monitoring is one of the ways that foundation is used.
In fact, telemetry is like the nervous system, constantly gathering signals from every part of the body. Monitoring is like the brain, interpreting those signals and deciding what needs attention. Telemetry feeds monitoring. Without telemetry, there is nothing to monitor. Without monitoring, telemetry remains a raw signal with no clear action attached.
What Is a Telemetry Pipeline?
A telemetry pipeline is the operating layer between telemetry sources and telemetry destinations. It collects signals from applications, hosts, cloud platforms, APIs, identity systems, endpoints, and networks, then processes that data before sending it onward.
The easiest way to think about it is that telemetry sources produce data, but the pipeline gives that data direction. Without a pipeline, downstream tools become catch-all warehouses. With a pipeline, telemetry can be standardized, routed by value, and governed according to policy. That is especially important for security operations, where one class of data may need real-time detection while another belongs in lower-cost retention or long-term investigation storage.
From a business perspective, the value is straightforward:
- Lower cost by reducing unnecessary downstream ingestion
- Better signal quality through normalization and enrichment
- Less analyst fatigue by cutting noisy, low-value events earlier
- More flexibility to send each data type where it creates the most value
- Stronger governance through filtering, redaction, and policy-based routing
How Does the Telemetry Pipeline Work?
At a high level, a telemetry pipeline works through three core stages: ingest, process, and route. Together, these stages turn raw telemetry from many sources into clean, useful data to act on.
Ingest
The first stage is ingestion. This is where the pipeline collects telemetry from across the environment: applications, cloud services, containers, endpoints, identity systems, network tools, and infrastructure components. In modern environments, this stage must handle multiple signal types at once, including logs, metrics, traces, and events, often arriving at very different volumes and speeds.
Process
The second stage is processing, and this is where most of the value is created. Data is cleaned, normalized, enriched, filtered, and optimized before it reaches downstream systems. That can include removing duplicates, standardizing schemas, enriching records with identity or threat context, redacting sensitive fields, or reducing noisy data that creates cost without adding much value.
This is also where optimization and governance come in. Instead of treating all telemetry as equally important, teams can shape data according to business and security priorities. High-value signals can be enriched and preserved. Low-value records can be reduced, tiered, or dropped. Sensitive information can be handled according to the compliance policy. In other words, processing is where the pipeline stops being a transport mechanism and becomes a control mechanism.
Route
The final stage is routing. Once telemetry has been shaped, the pipeline sends it to the right destinations. Security-relevant events may go to a SIEM or an in-stream detection layer. Operational metrics may go to observability tooling. Bulk logs may go to lower-cost storage. Archived data may be retained for compliance or long-term investigation. The point is that the same data no longer has to go everywhere in the same form.
By integrating collection, processing, and routing into one flow, a telemetry pipeline turns data from a flood into a controlled stream. It does not just move telemetry. It makes telemetry usable.
What Kind of Companies Need Telemetry Data Pipelines?
Any company running modern digital systems needs telemetry. The real difference is how urgently it needs to manage that telemetry well. Telemetry pipelines become especially important when blind spots are expensive, which usually means complex infrastructure, regulated data, customer-facing services, or constant security pressure. AWS’s observability guidance is explicitly built for cloud, hybrid, and on-prem environments, which already describes most enterprise estates.
That need shows up across many industries. Technology and SaaS companies rely on telemetry pipelines to protect uptime and customer experience. Financial institutions use them to monitor transactions, improve fraud detection, and keep audit data under control. Healthcare organizations use them to balance reliability with privacy and compliance. Retailers, telecom providers, manufacturers, logistics firms, and public-sector agencies need them because scale and continuity leave very little room for guesswork.
For security teams, the case is even sharper. Telemetry becomes the evidence layer behind detection, triage, investigation, and response. That is why the better question is no longer whether a company needs telemetry, but whether it is still treating telemetry like raw exhaust, or finally managing it like the strategic asset it has become.
How SOC Prime Turns Telemetry Pipelines Into Detection Pipelines
Telemetry pipelines started as a smarter way to move, shape, and control data before it reached expensive downstream platforms. SOC Prime extends that idea further with DetectFlow, which turns the pipeline into an active detection layer instead of using it only for transport and optimization.
DetectFlow can run tens of thousands of Sigma detections on live Kafka streams, chain detections at line speed, drastically reduce the volume of potential alerts, and surface attack chains that are then further correlated and pre-triaged by Agentic AI before they hit the SIEM. It also brings real-time visibility, in-flight tagging and enrichment, and ensures infrastructure scalability that goes beyond traditional SIEM limits. That moves detection left, closer to the data, earlier in the flow, and far less dependent on costly downstream solutions.
For cybersecurity teams, that is the larger takeaway. Telemetry pipelines are not just an observability upgrade or a cost-control tactic. They are becoming a core part of modern cyber defense. And when detection logic, correlation, and AI move into the pipeline itself, telemetry stops being just something teams store and search later, instead acting on it in real time.
The post Telemetry Pipeline: How It Works and Why It Matters in 2026 appeared first on SOC Prime.