Imagine this: You’re sipping your morning coffee and scrolling through your emails, when you spot it—a vulnerability report for your open source project. It’s your first one. Panic sets in. What does this mean? Where do you even start?
Many maintainers face this moment without a clear roadmap, but the good news is that handling vulnerability reports doesn’t have to be stressful. Below, we’ll show you that with the right tools and a step-by-step approach, you can tackle security issues efficiently and confidently.
Let’s dig in.
If you discovered that the lock on your front door was faulty, would you attach a note announcing it to everyone passing by? Of course not! Instead, you’d quietly tell the people who need to know—your family or housemates—so you can fix it before it becomes a real safety risk.
That’s exactly how vulnerability disclosure should be handled. Security issues aren’t just another bug. They can be a blueprint for attackers if exposed too soon. Instead of discussing them in the open, maintainers should work with security researchers behind the scenes to fix problems before they become public.
This approach, known as Coordinated Vulnerability Disclosure (CVD), keeps your users safe while giving you time to resolve the issue properly.
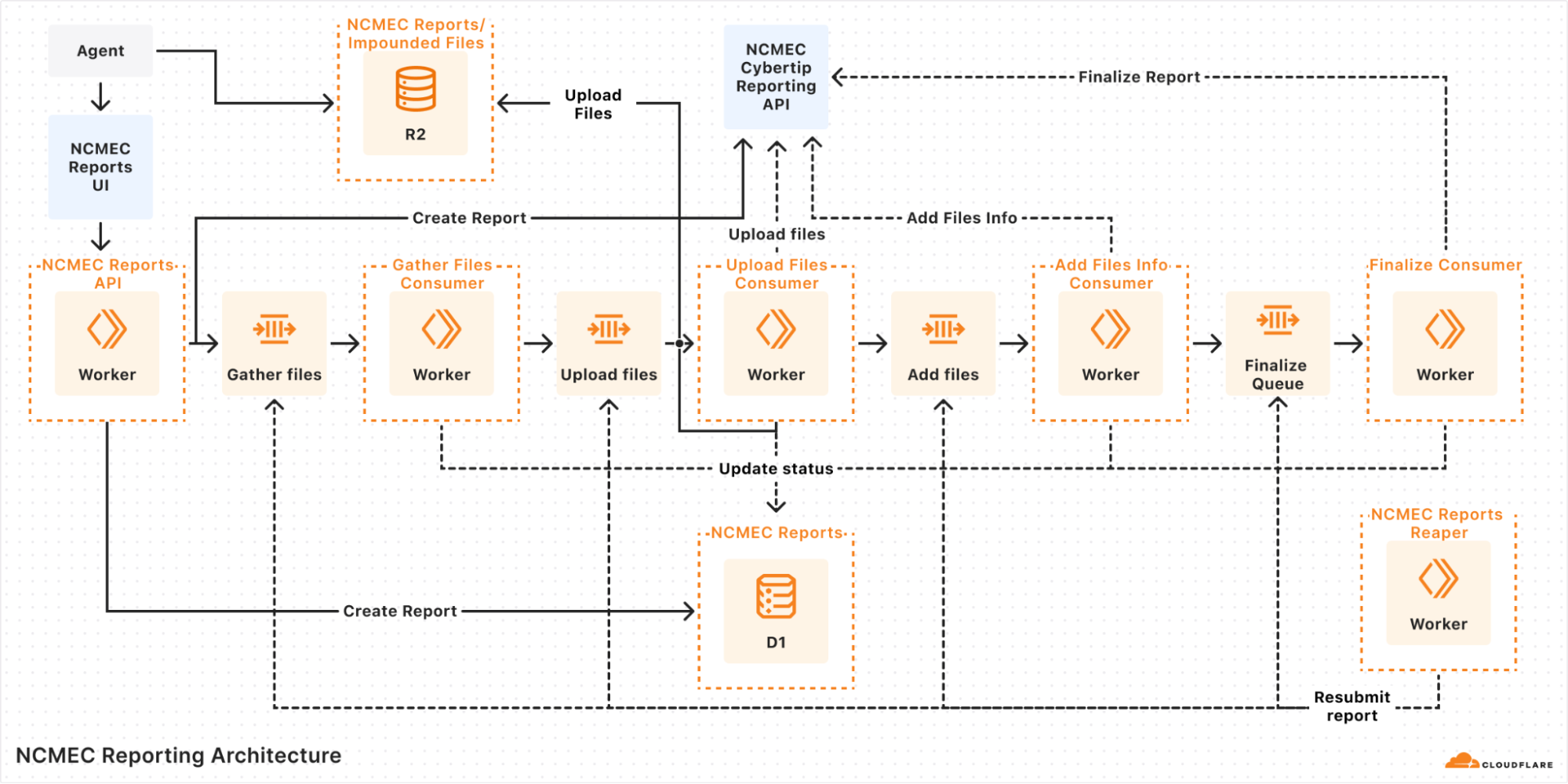
To support maintainers in this process, GitHub provides tools like Private Vulnerability Reporting (PVR), draft security advisories, and Dependabot alerts. These tools are free to use for open source projects, and are designed to make managing vulnerabilities straightforward and effective.
Let’s walk through how to handle vulnerability reports, so that the next time one lands in your inbox, you’ll know exactly what to do!
Here’s a quick overview of what you should do if you receive a vulnerability report:
- Enable Private Vulnerability Reporting (PVR) to handle submissions securely.
- Collaborate on a fix: Use draft advisories to plan and test resolutions privately.
- Request a Common Vulnerabilities and Exposures (CVE) identifier: Learn how to assign a CVE to your advisory for broader visibility.
- Publish the advisory: Notify your community about the issue and the fix.
- Notify and protect users: Utilize tools like Dependabot for automated updates.
Now, let’s break down each step.

Here’s the thing: There are security researchers out there actively looking for vulnerabilities in open source projects and trying to help. But if they don’t know who to report the problem to, it’s hard to resolve it. They could post the issue publicly, but this could expose users to attacks before there’s a fix. They could send it to the wrong person and delay the response. Or they could give up and move on.
The best way to ensure these researchers can reach you easily and safely is to turn on GitHub’s Private Vulnerability Reporting (PVR).
Think of PVR as a private inbox for security issues. It provides a built-in, confidential way for security researchers to report vulnerabilities directly in your repository.
🔗 How to enable PVR for a repository or an organization.
Heads up! By default, maintainers don’t receive notifications for new PVR reports, so be sure to update your notification settings so nothing slips through the cracks.
PVR solves the “where” and the “how” of reporting security issues. But what if you want to set clear expectations from the start? That’s where a SECURITY.md file comes in handy.
PVR is your front door, and SECURITY.md is your welcome guide telling visitors what to do when they arrive. Without it, researchers might not know what’s in scope, what details you need, or whether their report will be reviewed.
Maintainers are constantly bombarded with requests, making triage difficult—especially if reports are vague or missing key details. A well-crafted SECURITY.md helps cut through the noise by defining expectations early. It reassures researchers that their contributions are valued while giving them a clear framework to follow.
A good SECURITY.md file includes:
- How to report vulnerabilities (ex: “Please submit reports through PVR.”)
- What information should be included in a report (e.g., steps to reproduce, affected versions, etc.)
Pairing PVR with a clear SECURITY.md file helps you streamline incoming reports more effectively, making it easier for researchers to submit useful details and for you to act on them efficiently.

Once you confirm the issue is a valid vulnerability, the next step is fixing it without tipping off the wrong people.
But where do you discuss the details? You can’t just drop a fix in a public pull request and hope no one notices. If attackers spot the change before the fix is officially released, they can exploit it before users can update.
What you’ll need is a private space where you and your collaborators can investigate the issue, work on and test a fix, and then coordinate its release.
GitHub provides that space with draft security advisories. Think of them like a private fork, but specifically for security fixes.
- They keep your discussion private, so that you can work privately with your team or trusted contributors without alerting bad actors.
- They centralize everything, so your discussions, patches, and plans are kept in a secure workspace.
- They’re ready for publishing when you are: You can convert your draft advisory into a public advisory whenever you’re ready.
🔗 How to create a draft advisory.
By using draft security advisories, you take control of the disclosure timeline, ensuring security issues are fixed before they become public knowledge.

Some vulnerabilities are minor contained issues that can be patched quietly. Others have a broader impact and need to be tracked across the industry.
When a vulnerability needs broader visibility, a Common Vulnerabilities and Exposures (CVE) identifier provides a standardized way to document and reference it. GitHub allows maintainers to request a CVE directly from their draft security advisory, making the process seamless.
A CVE is like a serial number for a security vulnerability. It provides an industry-recognized reference so that developers, security teams, and automated tools can consistently track and respond to vulnerabilities.
- For maintainers, it helps ensure a vulnerability is adequately documented and recognized in security databases.
- For security researchers, it provides validation that their findings have been acknowledged and recorded.
CVEs are used in security reports, alerts, feeds, and automated security tools. This helps standardize communication between projects, security teams, and end users.
Requesting a CVE doesn’t make a vulnerability more or less critical, but it does help ensure that those affected can track and mitigate risks effectively.
🔗 How to request a CVE.
Once assigned, the CVE is linked to your advisory but will remain private until you publish it.
By requesting a CVE when appropriate, you’re helping improve visibility and coordination across the industry.

Good job! You’ve fixed the vulnerability. Now, it’s time to let your users know about it. A security advisory does more than just announce an issue. It guides your users on what to do next.
What is a security advisory, and why does it matter?
A security advisory is like a press release for an important update. It’s not just about disclosing a problem, it’s about ensuring your users know exactly what’s happening, why it matters, and what they need to do.
A clear and well-written advisory helps to:
- Inform users: Clearly explain the issue and provide instructions for fixing it.
- Build trust: Demonstrate accountability and transparency by addressing vulnerabilities proactively.
- Trigger automated notifications: Tools, like GitHub Dependabot, use advisories to alert developers with affected dependencies.
🔗 How to publish a security advisory.
Once published, the advisory becomes public in your repository and includes details about the vulnerability and how to fix it.
- Use plain language: Write in a way that’s easy to understand for both developers and non-technical users
- Include essential details:
- A description of the vulnerability and its impact
- Versions affected by the issue
- Steps to update, patch, or mitigate the risk
- Provide helpful resources:
- Links to patched versions or updated dependencies
- Workarounds for users who can’t immediately apply the fix
- Additional documentation or best practices
📌 Check out this advisory for a well-structured reference.
A well-crafted security advisory is not just a formality. It’s a roadmap that helps your users stay secure. Just as a company would carefully craft a press release for a significant change, your advisory should be clear, reassuring, and actionable. By making security easier to understand, you empower your users to protect themselves and keep their projects safe.
Publishing your security advisory isn’t the finish line. It’s the start of helping your users stay protected. Even the best advisory is only effective if the right people see it and take action.
Beyond publishing the advisory, consider:
- Announcing it through your usual channels: Blog posts, mailing lists, release notes, and community forums help reach users who may not rely on automated alerts.
- Documenting it for future users: Someone might adopt your project later without realizing a past version had a security issue. Keep advisories accessible and well-documented.
You should also take advantage of GitHub tools, including:
- Dependabot alerts
- Automatically informs developers using affected dependencies
- Encourages updates by suggesting patched versions
- Proactive prevention
- Use scanning tools to find similar problems in different parts of your project. If you find a problem in one area, it might also exist elsewhere
- Regularly review and update your project’s dependencies to avoid known issues
- CVE publication and advisory database
- If you requested a CVE, GitHub will publish the CVE record to CVE.org for industry-wide tracking
- If eligible, your advisory will also be added to the GitHub Advisory Database, improving visibility for security researchers and developers
Whether through automated alerts or direct communication, making your advisory visible is key to keeping your project and its users secure.
With the right tools and a clear approach, handling vulnerabilities isn’t just manageable—it’s part of running a strong, secure project. So next time a report comes in, take a deep breath. You’ve got this!

You’ve got questions? We got answers! Whether you’re handling your first vulnerability report or just want to sharpen your response process, here is what you need to know.
1. Why is Private Vulnerability Reporting (PVR) better than emails or public issues for vulnerability reports?
Great question! At first glance, email or public issue tracking might seem like simple ways to handle vulnerability reports. But PVR is a better choice because it:
- Keeps things private and secure: PVR ensures that sensitive details stay confidential. No risk of accidental leaks, and no need to juggle security concerns over email.
- Keeps everything in one place: No more scattered emails or external tools. Everything—discussions, reports, and updates—is neatly stored right in your repository.
- Makes it easier for researchers: PVR gives researchers a dedicated, structured way to report issues without jumping through hoops.
Bottom line? PVR makes life easier for both maintainers and researchers while keeping security under control.
2. What steps should I take if I receive a vulnerability report that I believe is a false positive?
Not every report is a real security issue, but it’s always worth taking a careful look before dismissing it.
- Double-check details: Sometimes, what seems like a false alarm might be misunderstood. Review the details thoroughly.
- Ask for more information: Ask clarifying questions or request additional details through GitHub’s PVR. Many researchers are happy to provide further context.
- Check with others: If you’re unsure, bring in a team member or a security-savvy friend to help validate the report.
- Close the loop: If it is a false positive, document your reasoning in the PVR thread. Transparency keeps things professional and builds trust with the researcher.
3. How fast do I need to respond?
* Acknowledge ASAP: Even if you don’t have a fix yet, let the researcher know you got their report. A simple “Thanks, we’re looking into it” goes a long way.
* Follow the 90-day best practice: While there’s no hard rule, most security pros aim to address verified vulnerabilities within 90 days.
* Prioritize by severity: Use the Common Vulnerability Scoring System (CVSS) to gauge urgency and decide what to tackle first.
Think of it this way: No one likes being left in the dark. A quick update keeps researchers engaged and makes collaboration smoother.
4. How do I figure out the severity of a reported vulnerability?
Severity can be tricky, but don’t stress! There are tools and approaches that make it easier.
- Use the CVSS calculator: It gives you a structured way to evaluate the impact and exploitability of a vulnerability.
- Consider real-world impact: A vulnerability that requires special conditions to exploit might be lower risk, while one that can be triggered easily by any user could be more severe.
- Collaborate with the reporter: They might have insights on how the issue could be exploited in real-world scenarios.
Take it step by step—it’s better to get it right than to rush.
5. Should I request a CVE before or after publishing an advisory?
There’s no one-size-fits-all answer, but here’s a simple way to decide:
- If it’s urgent: Publish the advisory first, then request a CVE. CVE assignments can take 1–3 days, and you don’t want to delay the fix.
- For less urgent cases: Request a CVE beforehand to ensure it’s included in Dependabot alerts from the start.
Either way, your advisory gets published, and your users stay informed.
6. Where can I learn more about managing vulnerabilities and security practices?
There’s no need to figure everything out on your own. These resources can help:
Security is an ongoing journey, and every step you take makes your projects stronger. Keep learning, stay proactive, and you’ll be in great shape.
By taking these steps, you’re protecting your project and contributing to a safer and more secure open source ecosystem.
The post A maintainer’s guide to vulnerability disclosure: GitHub tools to make it simple appeared first on The GitHub Blog.