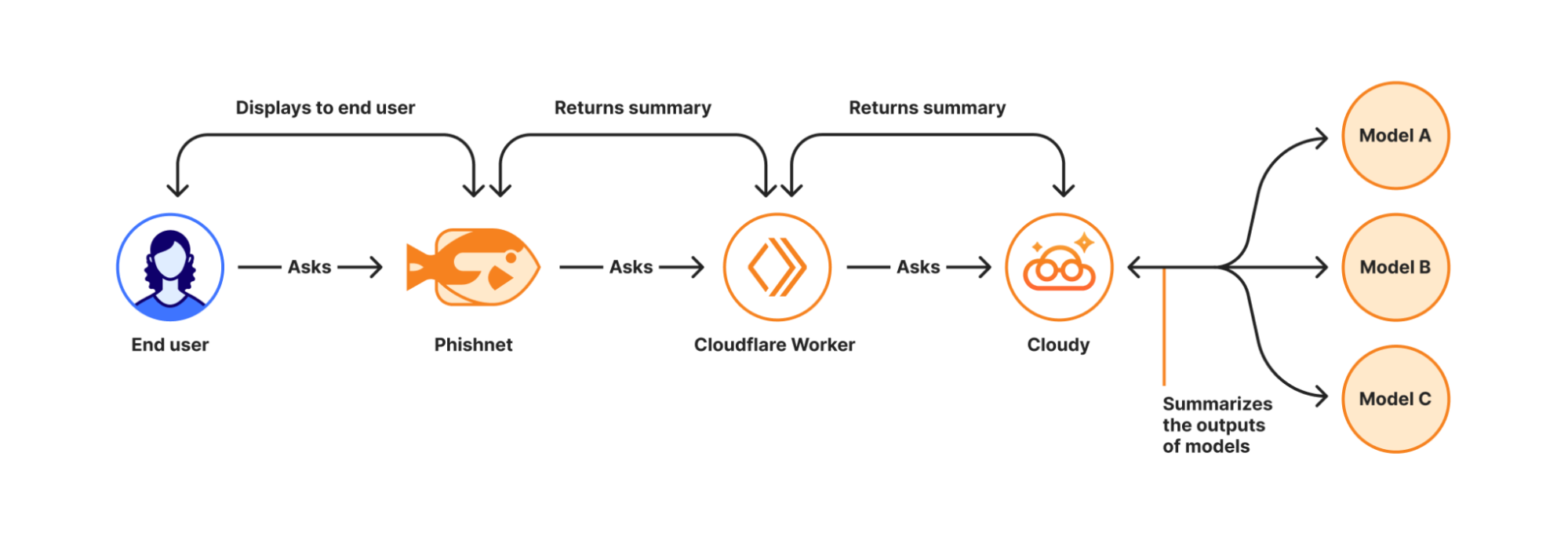
We at Cloudflare have aggressively adopted Model Context Protocol (MCP) as a core part of our AI strategy. This shift has moved well beyond our engineering organization, with employees across product, sales, marketing, and finance teams now using agentic workflows to drive efficiency in their daily tasks. But the adoption of agentic workflow with MCP is not without its security risks. These range from authorization sprawl, prompt injection, and supply chain risks. To secure this broad company-wide adoption, we have integrated a suite of security controls from both our Cloudflare One (SASE) platform and our Cloudflare Developer platform, allowing us to govern AI usage with MCP without slowing down our workforce.
In this blog we’ll walk through our own best practices for securing MCP workflows, by putting different parts of our platform together to create a unified security architecture for the era of autonomous AI. We’ll also share two new concepts that support enterprise MCP deployments:
We are launching Code Mode with MCP server portals, to drastically reduce token costs associated with MCP usage;
We describe how to use Cloudflare Gateway for Shadow MCP detection, to discover use of unauthorized remote MCP servers.
We also talk about how our organization approached deploying MCP, and how we built out our MCP security architecture using Cloudflare products including remote MCP servers, Cloudflare Access, MCP server portals and AI Gateway.
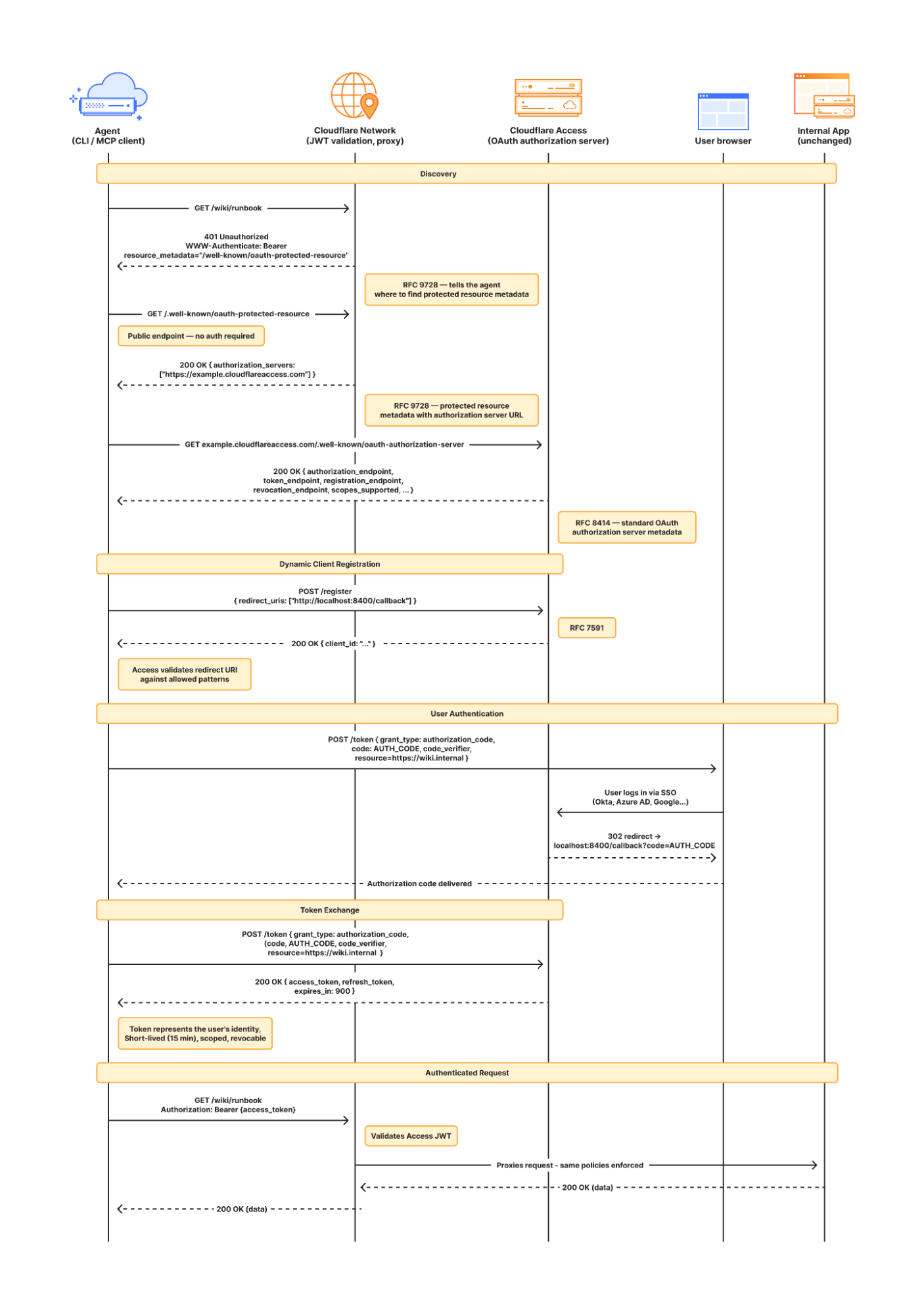
MCP is an open standard that enables developers to build a two-way connection between AI applications and the data sources they need to access. In this architecture, the MCP client is the integration point with the LLM or other AI agent, and the MCP server sits between the MCP client and the corporate resources.

The separation between MCP clients and MCP servers allows agents to autonomously pursue goals and take actions while maintaining a clear boundary between the AI (integrated at the MCP client) and the credentials and APIs of the corporate resource (integrated at the MCP server).
Our workforce at Cloudflare is constantly using MCP servers to access information in various internal resources, including our project management platform, our internal wiki, documentation and code management platforms, and more.
Very early on, we realized that locally-hosted MCP servers were a security liability. Local MCP server deployments may rely on unvetted software sources and versions, which increases the risk of supply chain attacks or tool injection attacks. They prevent IT and security administrators from administrating these servers, leaving it up to individual employees and developers to choose which MCP servers they want to run and how they want to keep them up to date. This is a losing game.

Instead, we have a centralized team at Cloudflare that manages our MCP server deployment across the enterprise. This team built a shared MCP platform inside our monorepo that provides governed infrastructure out of the box. When an employee wants to expose an internal resource via MCP, they first get approval from our AI governance team, and then they copy a template, write their tool definitions, and deploy, all the while inheriting default-deny write controls with audit logging, auto-generated CI/CD pipelines, and secrets management for free. This means standing up a new governed MCP server is minutes of scaffolding. The governance is baked into the platform itself, which is what allowed adoption to spread so quickly.
Our CI/CD pipeline deploys them as remote MCP servers on custom domains on Cloudflare’s developer platform. This gives us visibility into which MCPs servers are being used by our employees, while maintaining control over software sources. As an added bonus, every remote MCP server on the Cloudflare developer platform is automatically deployed across our global network of data centers, so MCP servers can be accessed by our employees with low latency, regardless of where they might be in the world.
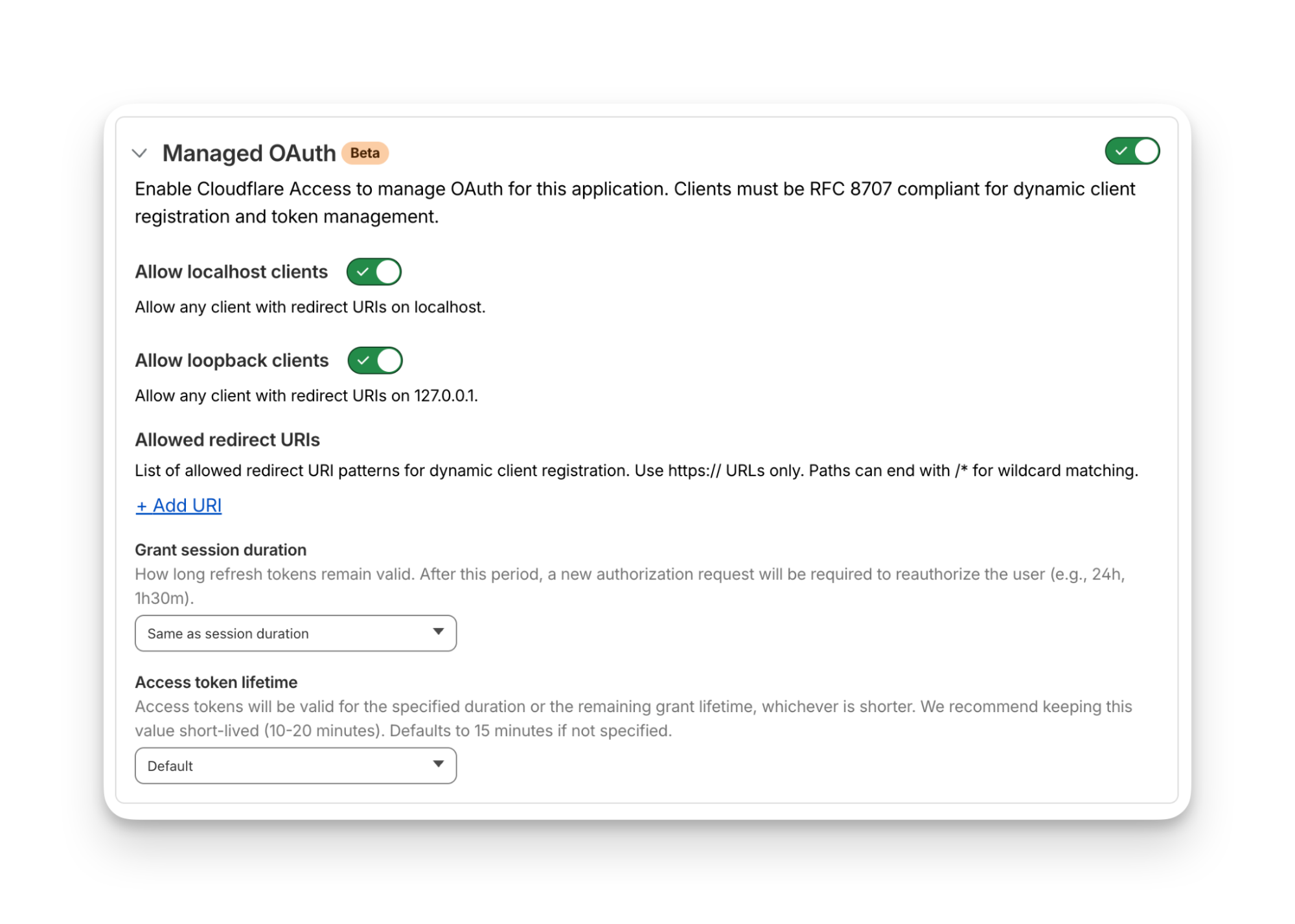
Some of our MCP servers sit in front of public resources, like our Cloudflare documentation MCP server or Cloudflare Radar MCP server, and thus we want them to be accessible to anyone. But many of the MCP servers used by our workforce are sitting in front of our private corporate resources. These MCP servers require user authentication to ensure that they are off limits to everyone but authorized Cloudflare employees. To achieve this, our monorepo template for MCP servers integrates Cloudflare Access as the OAuth provider. Cloudflare Access secures login flows and issues access tokens to resources, while acting as an identity aggregator that verifies end user single-sign on (SSO), multifactor authentication (MFA), and a variety of contextual attributes such as IP addresses, location, or device certificates.

MCP server portals unify governance and control for all AI activity.
As the number of our remote MCP servers grew, we hit a new wall: discovery. We wanted to make it easy for every employee (especially those that are new to MCP) to find and work with all the MCP servers that are available to them. Our MCP server portals product provided a convenient solution. The employee simply connects their MCP client to the MCP server portal, and the portal immediately reveals every internal and third-party MCP servers they are authorized to use.
Beyond this, our MCP server portals provide centralized logging, consistent policy enforcement and data loss prevention (DLP guardrails). Our administrators can see who logged into what MCP portal and create DLP rules that prevent certain data, like personally identifiable data (PII), from being shared with certain MCP servers.
We can also create policies that control who has access to the portal itself, and what tools from each MCP server should be exposed. For example, we could set up one MCP server portal that is only accessible to employees that are part of our finance group that exposes just the read-only tools for the MCP server in front of our internal code repository. Meanwhile, a different MCP server portal, accessible only to employees on their corporate laptops that are in our engineering team, could expose more powerful read/write tools to our code repository MCP server.
An overview of our MCP server portal architecture is shown above. The portal supports both remote MCP servers hosted on Cloudflare, and third-party MCP servers hosted anywhere else. What makes this architecture uniquely performant is that all these security and networking components run on the same physical machine within our global network. When an employee's request moves through the MCP server portal, a Cloudflare-hosted remote MCP server, and Cloudflare Access, their traffic never needs to leave the same physical machine.
After months of high-volume MCP deployments, we’ve paid out our fair share of tokens. We’ve also started to think most people are doing MCP wrong.
The standard approach to MCP requires defining a separate tool for every API operation that is exposed via an MCP server. But this static and exhaustive approach quickly exhausts an agent’s context window, especially for large platforms with thousands of endpoints.
We previously wrote about how we used server-side Code Mode to power Cloudflare’s MCP server, allowing us to expose the thousands of end-points in Cloudflare API while reducing token use by 99.9%. The Cloudflare MCP server exposes just two tools: a search tool lets the model write JavaScript to explore what’s available, and an execute tool lets it write JavaScript to call the tools it finds. The model discovers what it needs on demand, rather than receiving everything upfront.
We like this pattern so much, we had to make it available for everyone. So we have now launched the ability to use the “Code Mode” pattern with MCP server portals. Now you can front all of your MCP servers with a centralized portal that performs audit controls and progressive tool disclosure, in order to reduce token costs.
Here is how it works. Instead of exposing every tool definition to a client, all of your underlying MCP servers collapse into just two MCP portal tools: portal_codemode_search and portal_codemode_execute. The search tool gives the model access to a codemode.tools() function that returns all the tool definitions from every connected upstream MCP server. The model then writes JavaScript to filter and explore these definitions, finding exactly the tools it needs without every schema being loaded into context. The execute tool provides a codemode proxy object where each upstream tool is available as a callable function. The model writes JavaScript that calls these tools directly, chaining multiple operations, filtering results, and handling errors in code. All of this runs in a sandboxed environment on the MCP server portal powered by Dynamic Workers.
Here is an example of an agent that needs to find a Jira ticket and update it with information from Google Drive. It first searches for the right tools:
// portal_codemode_search
async () => {
const tools = await codemode.tools();
return tools
.filter(t => t.name.includes("jira") || t.name.includes("drive"))
.map(t => ({ name: t.name, params: Object.keys(t.inputSchema.properties || {}) }));
}
The model now knows the exact tool names and parameters it needs, without the full schemas of tools ever entering its context. It then writes a single execute call to chain the operations together:
// portal_codemode_execute
async () => {
const tickets = await codemode.jira_search_jira_with_jql({
jql: ‘project = BLOG AND status = “In Progress”’,
fields: [“summary”, “description”]
});
const doc = await codemode.google_workspace_drive_get_content({
fileId: “1aBcDeFgHiJk”
});
await codemode.jira_update_jira_ticket({
issueKey: tickets[0].key,
fields: { description: tickets[0].description + “\n\n” + doc.content }
});
return { updated: tickets[0].key };
}
This is just two tool calls. The first discovers what's available, the second does the work. Without Code Mode, this same workflow would have required the model to receive the full schemas of every tool from both MCP servers upfront, and then make three separate tool invocations.
Let’s put the savings in perspective: when our internal MCP server portal is connected to just four of our internal MCP servers, it exposes 52 tools that consume approximately 9,400 tokens of context just for their definitions. With Code Mode enabled, those 52 tools collapse into 2 portal tools consuming roughly 600 tokens, a 94% reduction. And critically, this cost stays fixed. As we connect more MCP servers to the portal, the token cost of Code Mode doesn’t grow.
Code Mode can be activated on an MCP server portal by adding a query parameter to the URL. Instead of connecting to your portal over its usual URL (e.g. https://myportal.example.com/mcp), you attach ?codemode=search_and_execute to the URL (e.g. https://myportal.example.com/mcp?codemode=search_and_execute).
We aren’t done yet. We plug AI Gateway into our architecture by positioning it on the connection between the MCP client and the LLM. This allows us to quickly switch between various LLM providers (to prevent vendor lock-in) and to enforce cost controls (by limiting the number of tokens each employee can burn through). The full architecture is shown below.

Now that we’ve provided governed access to authorized MCP servers, let’s look into dealing with unauthorized MCP servers. We can perform shadow MCP discovery using Cloudflare Gateway. Cloudflare Gateway is our comprehensive secure web gateway that provides enterprise security teams with visibility and control over their employees’ Internet traffic.
We can use the Cloudflare Gateway API to perform a multi-layer scan to find remote MCP servers that are not being accessed via an MCP server portal. This is possible using a variety of existing Gateway and Data Loss Prevention (DLP) selectors, including:
Using the Gateway
httpHostselector to scan forknown MCP server hostnames using (like mcp.stripe.com)
mcp.* subdomains using wildcard hostname patterns
Using the Gateway
httpRequestURIselector to scan for MCP-specific URL paths like /mcp and /mcp/sseUsing DLP-based body inspection to find MCP traffic, even if that traffic uses URI that do not contain the telltale mentions of
mcporsse. Specifically, we use the fact that MCP uses JSON-RPC over HTTP, which means every request contains a "method" field with values like "tools/call", "prompts/get", or "initialize." Here are some regex rules that can be used to detect MCP traffic in the HTTP body:
const DLP_REGEX_PATTERNS = [
{
name: "MCP Initialize Method",
regex: '"method"\\s{0,5}:\\s{0,5}"initialize"',
},
{
name: "MCP Tools Call",
regex: '"method"\\s{0,5}:\\s{0,5}"tools/call"',
},
{
name: "MCP Tools List",
regex: '"method"\\s{0,5}:\\s{0,5}"tools/list"',
},
{
name: "MCP Resources Read",
regex: '"method"\\s{0,5}:\\s{0,5}"resources/read"',
},
{
name: "MCP Resources List",
regex: '"method"\\s{0,5}:\\s{0,5}"resources/list"',
},
{
name: "MCP Prompts List",
regex: '"method"\\s{0,5}:\\s{0,5}"prompts/(list|get)"',
},
{
name: "MCP Sampling Create Message",
regex: '"method"\\s{0,5}:\\s{0,5}"sampling/createMessage"',
},
{
name: "MCP Protocol Version",
regex: '"protocolVersion"\\s{0,5}:\\s{0,5}"202[4-9]',
},
{
name: "MCP Notifications Initialized",
regex: '"method"\\s{0,5}:\\s{0,5}"notifications/initialized"',
},
{
name: "MCP Roots List",
regex: '"method"\\s{0,5}:\\s{0,5}"roots/list"',
},
];
The Gateway API supports additional automation. For example, one can use the custom DLP profile we defined above to block traffic, or redirect it, or just to log and inspect MCP payloads. Put this together, and Gateway can be used to provide comprehensive detection of unauthorized remote MCP servers accessed via an enterprise network.
For more information on how to build this out, see this tutorial.
So far, we’ve been focused on protecting our workforce’s access to our internal MCP servers. But, like many other organizations, we also have public-facing MCP servers that our customers can use to agentically administer and operate Cloudflare products. These MCP servers are hosted on Cloudflare’s developer platform. (You can find a list of individual MCPs for specific products here, or refer back to our new approach for providing more efficient access to the entire Cloudflare API using Code Mode.)
We believe that every organization should publish official, first-party MCP servers for their products. The alternative is that your customers source unvetted servers from public repositories where packages may contain dangerous trust assumptions, undisclosed data collection, and any range of unsanctioned behaviors. By publishing your own MCP servers, you control the code, update cadence, and security posture of the tools your customers use.
Since every remote MCP server is an HTTP endpoint, we can put it behind the Cloudflare Web Application Firewall (WAF). Customers can enable the AI Security for Apps feature within the WAF to automatically inspect inbound MCP traffic for prompt injection attempts, sensitive data leakage, and topic classification. Public facing MCPs are protected just as any other web API.
We hope our experience, products, and reference architectures will be useful to other organizations as they continue along their own journey towards broad enterprise-wide adoption of MCP.
We’ve secured our own MCP workflows by:
Offering our developers a templated framework for building and deploying remote MCP servers on our developer platform using Cloudflare Access for authentication
Ensuring secure, identity-based access to authorized MCP servers by connecting our entire workforce to MCP server portals
Controlling costs using AI Gateway to mediate access to the LLMs powering our workforce’s MCP clients, and using Code Mode in MCP server portals to reduce token consumption and context bloat
Discovering shadow MCP usage by Cloudflare Gateway
For organizations advancing on their own enterprise MCP journeys, we recommend starting by putting your existing remote and third-party MCP servers behind Cloudflare MCP server portals and enabling Code Mode to start benefitting for cheaper, safer and simpler enterprise deployments of MCP.
Acknowledgements: This reference architecture and blog represents this work of many people across many different roles and business units at Cloudflare. This is just a partial list of contributors: Ann Ming Samborski, Kate Reznykova, Mike Nomitch, James Royal, Liam Reese, Yumna Moazzam, Simon Thorpe, Rian van der Merwe, Rajesh Bhatia, Ayush Thakur, Gonzalo Chavarri, Maddy Onyehara, and Haley Campbell.