AI-driven and “legitimate” bots now make up a growing share of web traffic, blurring the line between value and risk. Security teams must treat bot traffic as a governance, cost, and cyber supply chain issue, guided by long-term visibility and analytics.
On the surface, the goal of handling bot traffic is clear: keep malicious bots away, while letting through the helpful ones. Some bots are evidently malicious — such as mass price scrapers or those testing stolen credit cards. Others are helpful, like the bots that index your website. Cloudflare has segmented this second category of helpful bot traffic through our verified bots program, vetting and validating bots that are transparent about who they are and what they do.
Today, the rise of agents has transformed how we interact with the Internet, often blurring the distinctions between benign and malicious bot actors. Bots are no longer directed only by the bot owners, but also by individual end users to act on their behalf. These bots directed by end users are often working in ways that website owners want to allow, such as planning a trip, ordering food, or making a purchase.
Our customers have asked us for easier, more granular ways to ensure specific bots, crawlers, and agents can reach their websites, while continuing to block bad actors. That’s why we’re excited to introduce signed agents, an extension of our verified bots program that gives a new bot classification in our security rules and in Radar. Cloudflare has long recognized agents — but we’re now endowing them with their own classification to make it even easier for our customers to set the traffic lanes they want for their website.
But the bot landscape is constantly evolving. Let's unpack a common type of verified AI bot — an AI crawler such as GPTBot. Even though the bot performs an array of tasks, the bot’s ultimate purpose is a singular, repetitive task on behalf of the operator of that bot: fetch and index information. Its intelligence is applied to performing that singular job on behalf of that bot owner.
Agents, though, are different. Think about an AI agent tasked by a user to "Book the best deal for a round-trip flight to New York City next month." These agents sometimes use remote browsing products like Cloudflare's Browser Rendering and similar products from companies like Browserbase and Anchor Browser. And here is the key distinction: this particular type of bot isn’t operating on behalf of a single company, like OpenAI in the prior example, but rather the end users themselves.
Introducing signed agents
In May, we announced Web Bot Auth, a new method of using cryptography to verify bot and agent traffic. HTTP message signatures allow bots to authenticate themselves and allow customer origins to identify them. This is one of the authentication methods we use today for our verified bots program.
What, exactly, is a signed agent? First, they are agents that are generally directed by an end user instead of a single company or entity. Second, the infrastructure or remote browsing platform the agents use is signing their HTTP requests via Web Both Auth, with Cloudflare validating these message signatures. And last, they comply with our signed agent policy.
The signed agents classification improves on our existing frameworks in a couple of ways:
Increased precision and visibility: we’ve updated the Cloudflare bots and agents directory to include signed agents in addition to verified bots. This allows us to verify the cryptographic signatures of a much wider set of automated traffic, and our customers to granularly apply their security preferences more easily. Bot operators can now submit signed agent applications from the Cloudflare dashboard, allowing bot owners to specify to us how they think we should segment their automated traffic.
Easier controls from security rules: similar to how they can take action on verified bots as a group, our Enterprise customers will be able to take action on signed agents as a group when configuring their security rules. This new field will be available in the Cloudflare dashboard under security rules soon.
To apply to have an agent added to Cloudflare’s directory of bots and agents, customers should complete the Bot Submission Form in the Cloudflare dashboard. Here, they can specify whether the submission should be considered for the signed agents list or the verified bots list. All signed agents will be recognized by their cryptographic signatures through Web Bot Auth validation.
The Bot Submission Form, available in the Cloudflare dashboard for bot owners to submit both verified bot and signed agent applications.
We want to be clear: our verified bots program isn’t going anywhere. In fact, well-behaved and transparent applications that make use of signed agents can further qualify to be a verified bot, if their specific service adheres to our policy. For instance,Cloudflare Radar's URL Scanner, which relies on Browser Rendering as a service to scan URLs, is a verified bot. While Browser Rendering itself does not qualify to be a verified bot, URL Scanner does, since the bot owner (in this case, Cloudflare Radar) directs the traffic sent by the bot and always identifies itself with a unique Web Bot Auth signature — distinct from Browser Rendering’s signature.
From an agent’s perspective…
Since the launch of Web Bot Auth, our own Browser Rendering product has been sending signed Web Bot Auth HTTP headers, and is always given a bot score of 1 for our Bot Management customers. As of today, Browser Rendering will now show up in this new signed agent category.
We’re also excited to announce the first cohort of agents that we’re partnering with and will be classifying as signed agents: ChatGPT agent, Goose from Block, Browserbase, and Anchor Browser. They are perfect examples of this new classification because their remote browsers are used by their end customers, not necessarily the companies themselves. We’re thrilled to partner with these teams to take this critical step for the AI ecosystem:
“When we built Goose as an open source tool, we designed it to run locally with an extensible architecture that lets developers automate complex workflows. As Goose has evolved to interact with external services and third-party sites on users' behalf, Web Bot Auth enables those sites to trust Goose while preserving what makes it unique. This authentication breakthrough unlocks entirely new possibilities for autonomous agents." – Douwe Osinga, Staff Software Engineer, Block
"At Browserbase, we provide web browsing capabilities for some of the largest AI applications. We're excited to partner with Cloudflare to support the adoption of Web Bot Auth, a critical layer of identity for agents. For AI to thrive, agents need reliable, responsible web access." – Paul Klein, CEO, Browserbase
“Anchor Browser has partnered with Cloudflare to let developers ship verified browser agents. This way trustworthy bots get reliable access while sites stay protected.” – Idan Raman, CEO, Anchor Browser
Updated visibility on Radar
We want everyone to be in the know about our bot classifications. Cloudflare began publishing verified bots on our Radar page back in 2022, meaning anyone on the Internet — Cloudflare customer or not — can see all of our verified bots on Radar. We dynamically update the list of bots, but show more than just a list: we announced on Content Independence Day that every verified bot would get its own page in our public-facing directory on Radar, which includes the traffic patterns that we see for each bot.
Our directory has been updated to include both signed agents and verified bots — we share exactly how Cloudflare classifies the bots that it recognizes, plus we surface all of the traffic that Cloudflare observes from these many recognized agents and bots. Through this updated directory, we’re not only giving better visibility to our customers, but also striving to set a higher standard for transparency of bot traffic on the Internet.
Cloudflare Radar’s Bots Directory, which lists verified bots and signed agents. This view is filtered to view only agent entries.
Cloudflare Radar’s signed agent page for ChatGPT agent, which includes its traffic patterns for the last 7 days, from August 21, 2025 to August 27, 2025.
What’s now, what’s next
As of today, the Cloudflare bot directory supports both bots and agents in a more clear-cut way, and customers or agent creators can submit agents to be signed and recognized through their account dashboard. In addition, anyone can see our signed agents and their traffic patterns on Radar. Soon, customers will be able to take action on signed agents as a group within their firewall rules, the same way you can take action on our verified bots.
Agents are changing the way that humans interact with the Internet. Websites need to know what tools are interacting with them, and for the builders of those tools to be able to easily scale. Message signatures help achieve both of these goals, but this is only step one. Cloudflare will continue to make it easier for agents and websites to interact (or not!) at scale, in a seamless way.
We are observing stealth crawling behavior from Perplexity, an AI-powered answer engine. Although Perplexity initially crawls from their declared user agent, when they are presented with a network block, they appear to obscure their crawling identity in an attempt to circumvent the website’s preferences. We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source ASNs to hide their crawling activity, as well as ignoring — or sometimes failing to even fetch — robots.txtfiles.
The Internet as we have known it for the past three decades is rapidly changing, but one thing remains constant: it is built on trust. There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences. Based on Perplexity’s observed behavior, which is incompatible with those preferences, we have de-listed them as a verified bot and added heuristics to our managed rules that block this stealth crawling.
How we tested
We received complaints from customers who had both disallowed Perplexity crawling activity in their robots.txt files and also created WAF rules to specifically block both of Perplexity’s declared crawlers: PerplexityBot and Perplexity-User. These customers told us that Perplexity was still able to access their content even when they saw its bots successfully blocked. We confirmed that Perplexity’s crawlers were in fact being blocked on the specific pages in question, and then performed several targeted tests to confirm what exact behavior we could observe.
We created multiple brand-new domains, similar to testexample.com and secretexample.com. These domains were newly purchased and had not yet been indexed by any search engine nor made publicly accessible in any discoverable way. We implemented a robots.txt file with directives to stop any respectful bots from accessing any part of a website:
We conducted an experiment by querying Perplexity AI with questions about these domains, and discovered Perplexity was still providing detailed information regarding the exact content hosted on each of these restricted domains. This response was unexpected, as we had taken all necessary precautions to prevent this data from being retrievable by their crawlers.
Obfuscating behavior observed
Bypassing Robots.txt and undisclosed IPs/User Agents
Our multiple test domains explicitly prohibited all automated access by specifying in robots.txt and had specific WAF rules that blocked crawling from Perplexity’s public crawlers. We observed that Perplexity uses not only their declared user-agent, but also a generic browser intended to impersonate Google Chrome on macOS when their declared crawler was blocked.
Declared
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user)
20-25m daily requests
Stealth
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
3-6m daily requests
Both their declared and undeclared crawlers were attempting to access the content for scraping contrary to the web crawling norms as outlined in RFC 9309.
This undeclared crawler utilized multiple IPs not listed in Perplexity’s official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks. This activity was observed across tens of thousands of domains and millions of requests per day. We were able to fingerprint this crawler using a combination of machine learning and network signals.
An example:
Of note: when the stealth crawler was successfully blocked, we observed that Perplexity uses other data sources — including other websites — to try to create an answer. However, these answers were less specific and lacked details from the original content, reflecting the fact that the block had been successful.
How well-meaning bot operators respect website preferences
In contrast to the behavior described above, the Internet has expressed clear preferences on how good crawlers should behave. All well-intentioned crawlers acting in good faith should:
Be transparent. Identify themselves honestly, using a unique user-agent, a declared list of IP ranges or Web Bot Auth integration, and provide contact information if something goes wrong.
Be well-behaved netizens. Don’t flood sites with excessive traffic, scrape sensitive data, or use stealth tactics to try and dodge detection.
Serve a clear purpose. Whether it’s powering a voice assistant, checking product prices, or making a website more accessible, every bot has a reason to be there. The purpose should be clearly and precisely defined and easy for site owners to look up publicly.
Separate bots for separate activities. Perform each activity from a unique bot. This makes it easy for site owners to decide which activities they want to allow. Don’t force site owners to make an all-or-nothing decision.
Follow the rules. That means checking for and respecting website signals like robots.txt, staying within rate limits, and never bypassing security protections.
OpenAI is an example of a leading AI company that follows these best practices. They clearly outline their crawlers and give detailed explanations for each crawler’s purpose. They respect robots.txt and do not try to evade either a robots.txt directive or a network level block. And ChatGPT Agent is signing http requests using the newly proposed open standard Web Bot Auth.
When we ran the same test as outlined above with ChatGPT, we found that ChatGPT-User fetched the robots file and stopped crawling when it was disallowed. We did not observe follow-up crawls from any other user agents or third party bots. When we removed the disallow directive from the robots entry, but presented ChatGPT with a block page, they again stopped crawling, and we saw no additional crawl attempts from other user agents. Both of these demonstrate the appropriate response to website owner preferences.
How can you protect yourself?
All the undeclared crawling activity that we observed from Perplexity’s hidden User Agent was scored by our bot management system as a bot and was unable to pass managed challenges. Any bot management customer who has an existing block rule in place is already protected. Customers who don’t want to block traffic can set up rules to challenge requests, giving real humans an opportunity to proceed. Customers with existing challenge rules are already protected. Lastly, we added signature matches for the stealth crawler into our managed rule that blocks AI crawling activity. This rule is available to all customers, including our free customers.
What’s next?
It's been just over a month since we announced Content Independence Day, giving content creators and publishers more control over how their content is accessed. Today, over two and a half million websites have chosen to completely disallow AI training through our managed robots.txt feature or our managed rule blocking AI Crawlers. Every Cloudflare customer is now able to selectively decide which declared AI crawlers are able to access their content in accordance with their business objectives.
We expected a change in bot and crawler behavior based on these new features, and we expect that the techniques bot operators use to evade detection will continue to evolve. Once this post is live the behavior we saw will almost certainly change, and the methods we use to stop them will keep evolving as well.
Cloudflare is actively working with technical and policy experts around the world, like the IETF efforts to standardize extensions to robots.txt, to establish clear and measurable principles that well-meaning bot operators should abide by. We think this is an important next step in this quickly evolving space.
Within the Cloudflare Application Security team, every machine learning model we use is underpinned by a rich set of static rules that serve as a ground truth and a baseline comparison for how our models are performing. These are called heuristics. Our Bot Management heuristics engine has served as an important part of eight global machine learning (ML) models, but we needed a more expressive engine to increase our accuracy. In this post, we’ll review how we solved this by moving our heuristics to the Cloudflare Ruleset Engine. Not only did this provide the platform we needed to write more nuanced rules, it made our platform simpler and safer, and provided Bot Management customers more flexibility and visibility into their bot traffic.
Bot detection via simple heuristics
In Cloudflare’s bot detection, we build heuristics from attributes like software library fingerprints, HTTP request characteristics, and internal threat intelligence. Heuristics serve three separate purposes for bot detection:
Bot identification: If traffic matches a heuristic, we can identify the traffic as definitely automated traffic (with a bot score of 1) without the need of a machine learning model.
Train ML models: When traffic matches our heuristics, we create labelled datasets of bot traffic to train new models. We’ll use many different sources of labelled bot traffic to train a new model, but our heuristics datasets are one of the highest confidence datasets available to us.
Validate models: We benchmark any new model candidate’s performance against our heuristic detections (among many other checks) to make sure it meets a required level of accuracy.
While the existing heuristics engine has worked very well for us, as bots evolved we needed the flexibility to write increasingly complex rules. Unfortunately, such rules were not easily supported in the old engine. Customers have also been asking for more details about which specific heuristic caught a request, and for the flexibility to enforce different policies per heuristic ID. We found that by building a new heuristics framework integrated into the Cloudflare Ruleset Engine, we could build a more flexible system to write rules and give Bot Management customers the granular explainability and control they were asking for.
The need for more efficient, precise rules
In our previous heuristics engine, we wrote rules in Lua as part of our openresty-based reverse proxy. The Lua-based engine was limited to a very small number of characteristics in a rule because of the high engineering cost we observed with adding more complexity.
With Lua, we would write fairly simple logic to match on specific characteristics of a request (i.e. user agent). Creating new heuristics of an existing class was fairly straight forward. All we’d need to do is define another instance of the existing class in our database. However, if we observed malicious traffic that required more than two characteristics (as a simple example, user-agent and ASN) to identify, we’d need to create bespoke logic for detections. Because our Lua heuristics engine was bundled with the code that ran ML models and other important logic, all changes had to go through the same review and release process. If we identified malicious traffic that needed a new heuristic class, and we were also blocked by pending changes in the codebase, we’d be forced to either wait or rollback the changes. If we’re writing a new rule for an “under attack” scenario, every extra minute it takes to deploy a new rule can mean an unacceptable impact to our customer’s business.
More critical than time to deploy is the complexity that the heuristics engine supports. The old heuristics engine only supported using specific request attributes when creating a new rule. As bots became more sophisticated, we found we had to reject an increasing number of new heuristic candidates because we weren’t able to write precise enough rules. For example, we found a Golang TLS fingerprint frequently used by bots and by a small number of corporate VPNs. We couldn’t block the bots without also stopping the legitimate VPN usage as well, because the old heuristics platform lacked the flexibility to quickly compile sufficiently nuanced rules. Luckily, we already had the perfect solution with Cloudflare Ruleset Engine.
Our new heuristics engine
The Ruleset Engine is familiar to anyone who has written a WAF rule, Load Balancing rule, or Transform rule, just to name a few. For Bot Management, the Wireshark-inspired syntax allows us to quickly write heuristics with much greater flexibility to vastly improve accuracy. We can write a rule in YAML that includes arbitrary sub-conditions and inherit the same framework the WAF team uses to both ensure any new rule undergoes a rigorous testing process with the ability to rapidly release new rules to stop attacks in real-time.
Writing heuristics on the Cloudflare Ruleset Engine allows our engineers and analysts to write new rules in an easy to understand YAML syntax. This is critical to supporting a rapid response in under attack scenarios, especially as we support greater rule complexity. Here’s a simple rule using the new engine, to detect empty user-agents restricted to a specific JA4 fingerprint (right), compared to the empty user-agent detection in the old Lua based system (left):
--- Adds heuristic to be used for inference in `detect` method
-- @param heuristic schema.Heuristic table
function EmptyUserAgentHeuristic:add(heuristic)
self.heuristic = heuristic
end
--- Detect runs empty user agent heuristic detection
-- @param ctx context of request
-- @return schema.Heuristic table on successful detection or nil otherwise
function EmptyUserAgentHeuristic:detect(ctx)
local ua = ctx.user_agent
if not ua or ua == '' then
return self.heuristic
end
end
return _M
ref: empty-user-agent
description: Empty or missing
User-Agent header
action: add_bot_detection
action_parameters:
active_mode: false
expression: http.user_agent eq
"" and cf.bot_management.ja4 = "t13d1516h2_8daaf6152771_b186095e22b6"
The Golang heuristic that captured corporate proxy traffic as well (mentioned above) was one of the first to migrate to the new Ruleset engine. Before the migration, traffic matching on this heuristic had a false positive rate of 0.01%. While that sounds like a very small number, this means for every million bots we block, 100 real users saw a Cloudflare challenge page unnecessarily. At Cloudflare scale, even small issues can have real, negative impact.
When we analyzed the traffic caught by this heuristic rule in depth, we saw the vast majority of attack traffic came from a small number of abusive networks. After narrowing the definition of the heuristic to flag the Golang fingerprint only when it’s sourced by the abusive networks, the rule now has a false positive rate of 0.0001% (One out of 1 million). Updating the heuristic to include the network context improved our accuracy, while still blocking millions of bots every week and giving us plenty of training data for our bot detection models. Because this heuristic is now more accurate, newer ML models make more accurate decisions on what’s a bot and what isn’t.
New visibility and flexibility for Bot Management customers
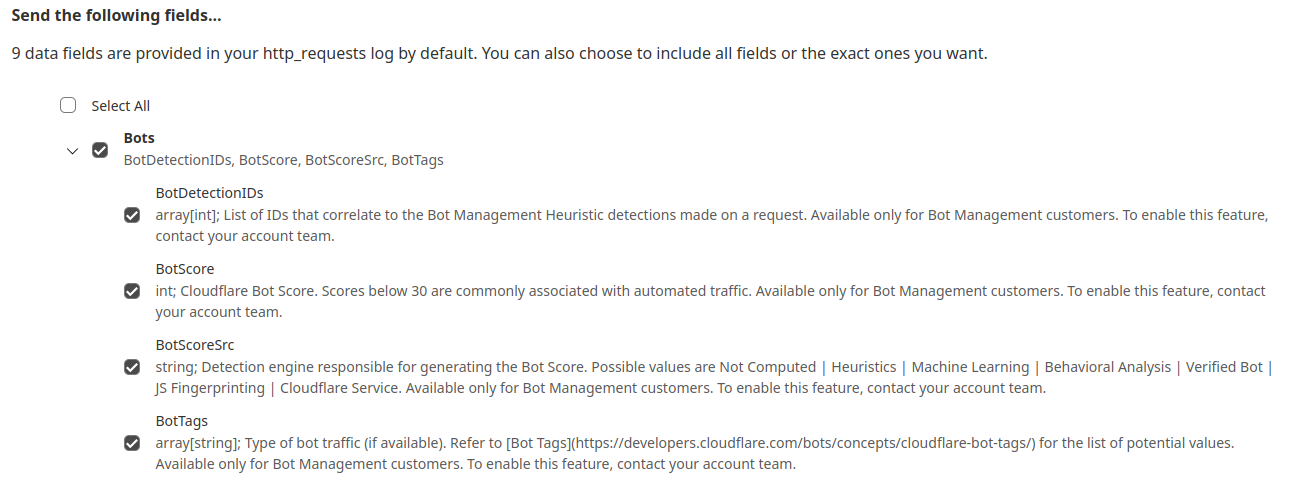
While the new heuristics engine provides more accurate detections for all customers and a better experience for our analysts, moving to the Cloudflare Ruleset Engine also allows us to deliver new functionality for Enterprise Bot Management customers, specifically by offering more visibility. This new visibility is via a new field for Bot Management customers called Bot Detection IDs. Every heuristic we use includes a unique Bot Detection ID. These are visible to Bot Management customers in analytics, logs, and firewall events, and they can be used in the firewall to write precise rules for individual bots.
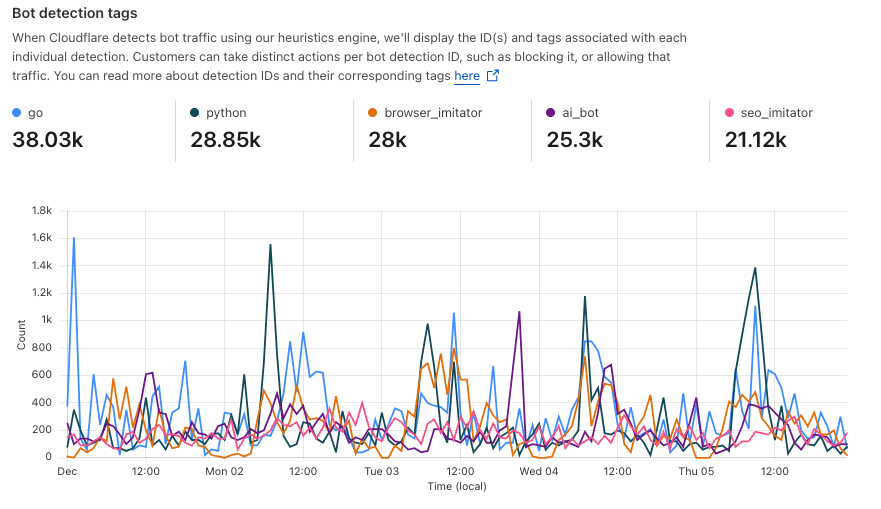
Detections also include a specific tag describing the class of heuristic. Customers see these plotted over time in their analytics.
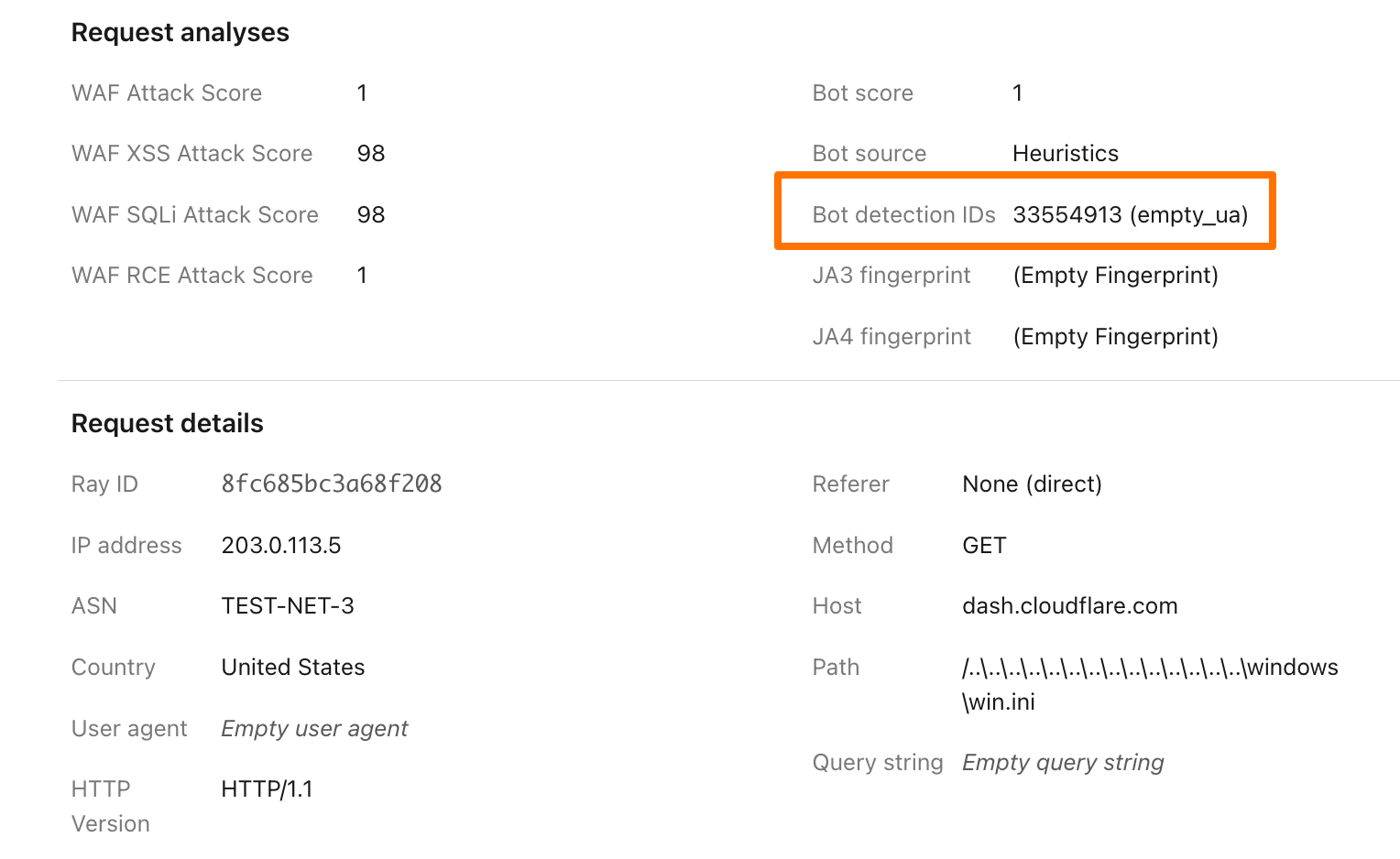
To illustrate how this data can help give customers visibility into why we blocked a request, here’s an example request flagged by Bot Management (with the IP address, ASN, and country changed):
Before, just seeing that our heuristics gave the request a score of 1 was not very helpful in understanding why it was flagged as a bot. Adding our Detection IDs to Firewall Events helps to paint a better picture for customers that we’ve identified this request as a bot because that traffic used an empty user-agent.
In addition to Analytics and Firewall Events, Bot Detection IDs are now available for Bot Management customers to use in Custom Rules, Rate Limiting Rules, Transform Rules, and Workers.
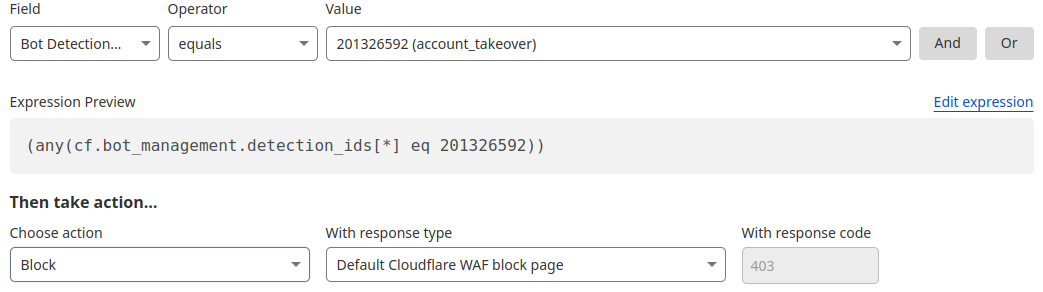
Account takeover detection IDs
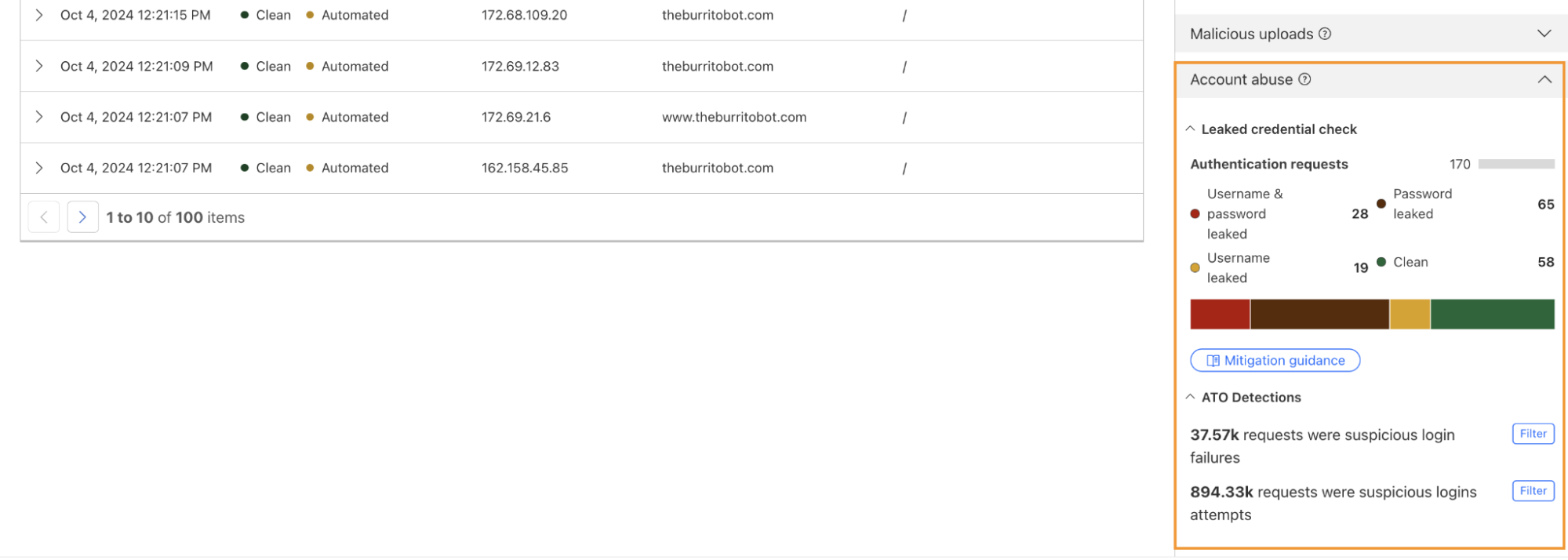
One way we’re focused on improving Bot Management for our customers is by surfacing more attack-specific detections. During Birthday Week, we launched Leaked Credentials Check for all customers so that security teams could help prevent account takeover (ATO) attacks by identifying accounts at risk due to leaked credentials. We’ve now added two more detections that can help Bot Management enterprise customers identify suspicious login activity via specific detection IDs that monitor login attempts and failures on the zone. These detection IDs are not currently affecting the bot score, but will begin to later in 2025. Already, they can help many customers detect more account takeover events now.
Detection ID 201326592 monitors traffic on a customer website and looks for an anomalous rise in login failures (usually associated with brute force attacks), and ID 201326593 looks for an anomalous rise in login attempts (usually associated with credential stuffing).
Protect your applications
If you are a Bot Management customer, log in and head over to the Cloudflare dashboard and take a look in Security Analytics for bot detection IDs 201326592 and 201326593.
These will highlight ATO attempts targeting your site. If you spot anything suspicious, or would like to be protected against future attacks, create a rule that uses these detections to keep your application safe.