Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives
We are observing stealth crawling behavior from Perplexity, an AI-powered answer engine. Although Perplexity initially crawls from their declared user agent, when they are presented with a network block, they appear to obscure their crawling identity in an attempt to circumvent the website’s preferences. We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source ASNs to hide their crawling activity, as well as ignoring — or sometimes failing to even fetch — robots.txt files.
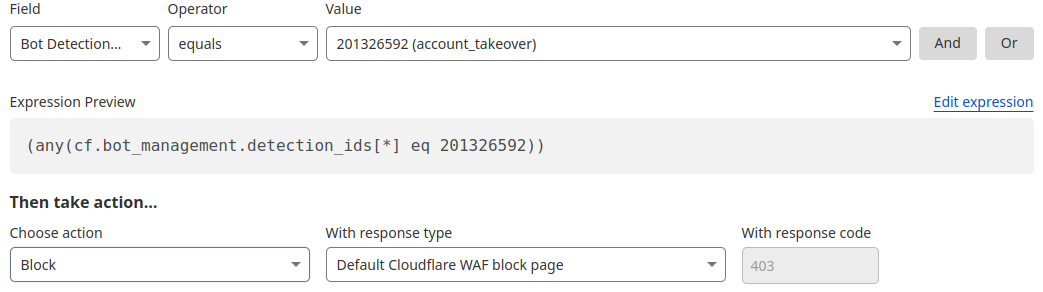
The Internet as we have known it for the past three decades is rapidly changing, but one thing remains constant: it is built on trust. There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences. Based on Perplexity’s observed behavior, which is incompatible with those preferences, we have de-listed them as a verified bot and added heuristics to our managed rules that block this stealth crawling.
We received complaints from customers who had both disallowed Perplexity crawling activity in their robots.txt files and also created WAF rules to specifically block both of Perplexity’s declared crawlers: PerplexityBot and Perplexity-User. These customers told us that Perplexity was still able to access their content even when they saw its bots successfully blocked. We confirmed that Perplexity’s crawlers were in fact being blocked on the specific pages in question, and then performed several targeted tests to confirm what exact behavior we could observe.
We created multiple brand-new domains, similar to testexample.com and secretexample.com. These domains were newly purchased and had not yet been indexed by any search engine nor made publicly accessible in any discoverable way. We implemented a robots.txt file with directives to stop any respectful bots from accessing any part of a website:

We conducted an experiment by querying Perplexity AI with questions about these domains, and discovered Perplexity was still providing detailed information regarding the exact content hosted on each of these restricted domains. This response was unexpected, as we had taken all necessary precautions to prevent this data from being retrievable by their crawlers.


Bypassing Robots.txt and undisclosed IPs/User Agents
Our multiple test domains explicitly prohibited all automated access by specifying in robots.txt and had specific WAF rules that blocked crawling from Perplexity’s public crawlers. We observed that Perplexity uses not only their declared user-agent, but also a generic browser intended to impersonate Google Chrome on macOS when their declared crawler was blocked.
Declared | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user) | 20-25m daily requests |
Stealth | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 | 3-6m daily requests |
Both their declared and undeclared crawlers were attempting to access the content for scraping contrary to the web crawling norms as outlined in RFC 9309.
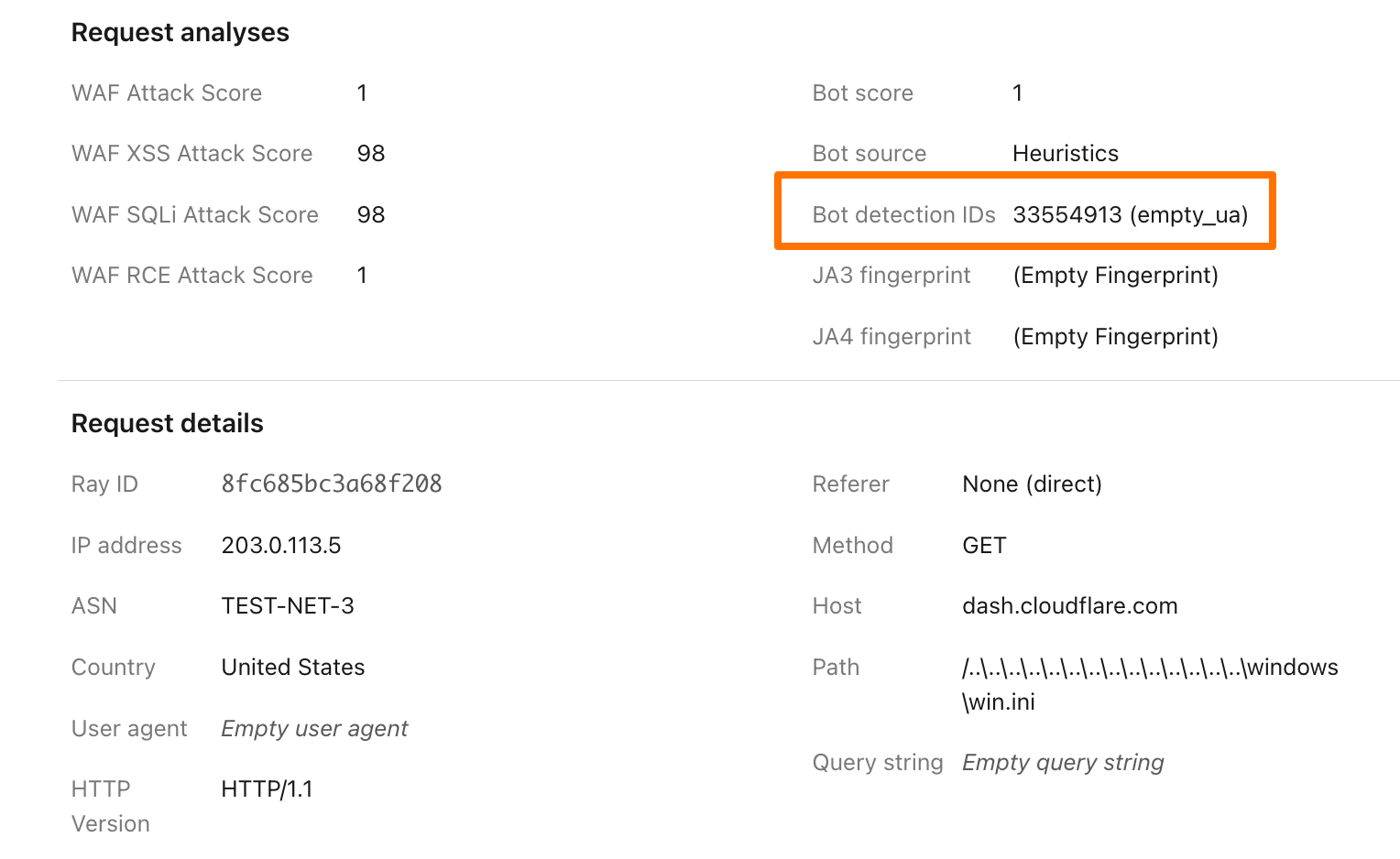
This undeclared crawler utilized multiple IPs not listed in Perplexity’s official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks. This activity was observed across tens of thousands of domains and millions of requests per day. We were able to fingerprint this crawler using a combination of machine learning and network signals.
An example:

Of note: when the stealth crawler was successfully blocked, we observed that Perplexity uses other data sources — including other websites — to try to create an answer. However, these answers were less specific and lacked details from the original content, reflecting the fact that the block had been successful.
In contrast to the behavior described above, the Internet has expressed clear preferences on how good crawlers should behave. All well-intentioned crawlers acting in good faith should:
Be transparent. Identify themselves honestly, using a unique user-agent, a declared list of IP ranges or Web Bot Auth integration, and provide contact information if something goes wrong.
Be well-behaved netizens. Don’t flood sites with excessive traffic, scrape sensitive data, or use stealth tactics to try and dodge detection.
Serve a clear purpose. Whether it’s powering a voice assistant, checking product prices, or making a website more accessible, every bot has a reason to be there. The purpose should be clearly and precisely defined and easy for site owners to look up publicly.
Separate bots for separate activities. Perform each activity from a unique bot. This makes it easy for site owners to decide which activities they want to allow. Don’t force site owners to make an all-or-nothing decision.
Follow the rules. That means checking for and respecting website signals like robots.txt, staying within rate limits, and never bypassing security protections.
More details are outlined in our official Verified Bots Policy Developer Docs.
OpenAI is an example of a leading AI company that follows these best practices. They clearly outline their crawlers and give detailed explanations for each crawler’s purpose. They respect robots.txt and do not try to evade either a robots.txt directive or a network level block. And ChatGPT Agent is signing http requests using the newly proposed open standard Web Bot Auth.
When we ran the same test as outlined above with ChatGPT, we found that ChatGPT-User fetched the robots file and stopped crawling when it was disallowed. We did not observe follow-up crawls from any other user agents or third party bots. When we removed the disallow directive from the robots entry, but presented ChatGPT with a block page, they again stopped crawling, and we saw no additional crawl attempts from other user agents. Both of these demonstrate the appropriate response to website owner preferences.

All the undeclared crawling activity that we observed from Perplexity’s hidden User Agent was scored by our bot management system as a bot and was unable to pass managed challenges. Any bot management customer who has an existing block rule in place is already protected. Customers who don’t want to block traffic can set up rules to challenge requests, giving real humans an opportunity to proceed. Customers with existing challenge rules are already protected. Lastly, we added signature matches for the stealth crawler into our managed rule that blocks AI crawling activity. This rule is available to all customers, including our free customers.
It's been just over a month since we announced Content Independence Day, giving content creators and publishers more control over how their content is accessed. Today, over two and a half million websites have chosen to completely disallow AI training through our managed robots.txt feature or our managed rule blocking AI Crawlers. Every Cloudflare customer is now able to selectively decide which declared AI crawlers are able to access their content in accordance with their business objectives.
We expected a change in bot and crawler behavior based on these new features, and we expect that the techniques bot operators use to evade detection will continue to evolve. Once this post is live the behavior we saw will almost certainly change, and the methods we use to stop them will keep evolving as well.
Cloudflare is actively working with technical and policy experts around the world, like the IETF efforts to standardize extensions to robots.txt, to establish clear and measurable principles that well-meaning bot operators should abide by. We think this is an important next step in this quickly evolving space.