A group of unauthorized users reportedly has gained access to Anthropic’s controversial Claude Mythos Preview AI frontier model despite the AI vendor’s efforts to keep it out of public hands by limiting the organizations that can use it. Bloomberg reported that the unnamed group had tried multiple ways to gain access to the AI model..
Revenue dips. Latency spikes. Alerts fire. The dashboards look fine – until they don’t
Slack explodes. Ten engineers become 20. Queries multiply. Everyone starts scanning raw event data at once. And then the system starts to buckle. Right when you need it most.
Over the past decade, I’ve worked on large-scale, real-time analytics systems for massive, bursty workloads. First in ad tech and more recently in observability. Across very different domains, the same failure pattern tends to emerge. Platforms that perform well under normal, steady-state conditions degrade under investigative load.
In many cases, this isn’t simply a matter of tuning or operational discipline. It reflects architectural assumptions. Most observability platforms were designed for detection-oriented workloads and not the unpredictable, exploratory way humans investigate incidents in real time.
Where the architecture breaks
Many observability platforms are built around a core assumption that queries will follow normal, predictable patterns. Dashboards, alerts and saved searches reflect known questions about the system.
But incidents aren’t predictable.
During an investigation, workloads shift instantly. Queries become exploratory. Time ranges expand. Filters change constantly. Concurrency spikes as multiple teams dig into the same data.
Architectural assumptions that work well in steady state can begin to show strain. Index-centric systems perform well on known paths. Step outside them, and performance drops quickly. Sub-second queries turn into minutes, concurrency falls off and costs rise.
Over time, teams may begin to limit the scope of analysis or to export data to other systems simply to maintain responsiveness.
This dynamic isn’t primarily about features. It reflects a structural mismatch between how many systems are designed and how investigations actually unfold.
These environments required a different architectural model.
Rather than optimizing around predefined views or tightly coupled indexing structures, event-native systems treat raw, immutable events as the primary unit of storage and analysis. Every request, error and interaction is preserved as an event and remains available for exploration.
Data is stored in column-oriented formats designed for large-scale scanning and high-cardinality queries. Instead of shaping the data upfront for specific access patterns, the system is built to support evolving questions directly against the event stream.
The difference becomes clear during an incident.
Imagine a latency spike affecting a subset of users. Engineers may need to pivot across user ID, region, service version or request path — combining dimensions that were not anticipated in advance.
In an event-native system, those pivots can occur directly against stored event data without rebuilding indexes or reshaping datasets for each new question. Multiple teams can run these queries concurrently, even across large time ranges, without the system degrading.
That’s the core shift: you’re no longer constrained by how the data was modeled upfront. You can investigate what actually happened, in real time, at scale.
Cloud economics changed the rules, but architectures stayed the same
Many observability architectures were designed for an era when storage was fixed (and expensive). That’s no longer the case. In the cloud, storage is abundant and cheap. Compute is elastic, which is often the real cost driver. You can store years of event data in object storage at a fraction of the cost of running always-on compute clusters. Yet many observability platforms still tightly couple storage, indexing and query compute as if nothing changed.
What does this mean in practice? You pay peak compute prices just to keep data available and accessible. This turns observability into making bad trade-offs between cost, retention and performance.
All-in-one observability platforms can be powerful, but they’re also rigid. When storage and compute scale together, you lose control over economics.
Monolithic architectures shine in steady state, but when incidents are triggered, they quickly become painfully expensive, painfully slow or both.
Why observability needs a dedicated data layer, not another all-in-one platform
For years, consolidation has been a common response in observability – one more all-in-one platform promising simplicity.
That approach can reduce surface complexity in the short term. Over time, however, tightly coupled systems can limit flexibility. As scale increases, storage, compute and visualization begin to compete for resources inside the same architecture.
Business intelligence learned this lesson decades ago. What started as tightly coupled stacks separated into a modular architecture where storage, transformation and visualization became independent layers. That separation created leverage and companies like Snowflake, Databricks, Fivetran and Tableau emerged by focusing on distinct parts of the stack.
Each layer could innovate independently. Storage could scale without changing dashboards or workflow, compute engines could evolve without changing ingestion and visualization tools could compete on experience rather than infrastructure.
Observability is next.
One architectural response is the introduction of a purpose-built data layer that sits beneath existing observability tools such as Splunk, Grafana or Kibana. By separating data storage from interaction and analysis, organizations can retain large volumes of telemetry while scaling compute based on investigative demand.
It means longer retention without constant peak compute costs. It means bursty, investigative workloads don’t collapse the system and multiple teams can dig into the same event stream without stepping on each other. It aligns the architecture with how observability admins and engineers actually work during incidents.
And critically so, it treats observability as a data infrastructure problem not just a tooling problem.
This shift breaks the lock between data and tools
In tightly integrated observability platforms, data is often bound to a specific query engine or user interface. That coupling can simplify adoption, but it also limits long-term flexibility. Storage decisions, retention policies and performance characteristics become tied to a single vendor’s architecture.
When the underlying event data layer is open, durable and scalable, organizations gain optionality. The same telemetry can be analyzed across multiple tools. Retention strategies can evolve independently of dashboards. New query engines or visualization systems can be adopted over time without migrating years of historical data.
That’s why new architectural patterns are emerging in large-scale deployments – systems designed for unpredictable query shapes and deep exploratory analysis. Architectures that separate storage, compute and indexing that treat observability as a data problem first.
When data is stored in open, scalable systems rather than locked inside a single platform, organizations gain flexibility. They can analyze the same data across multiple tools, adopt new technologies over time and avoid being constrained by the limitations or cost structures of any one vendor.
What the next decade of observability will look like
Telemetry volumes will continue to grow. Distributed systems introduce more surface area. AI workloads generate additional signals and amplify data scale. Investigations are becoming more collaborative and more exploratory.
In that environment, the defining characteristic of observability systems will not be the number of features they expose, but the architecture beneath them.
When Slack explodes and dashboards slow down with (or completely stop) answering the right questions, the architecture underneath will determine whether teams find the root cause in minutes or watch the system buckle all over again.
This article is published as part of the Foundry Expert Contributor Network. Want to join?
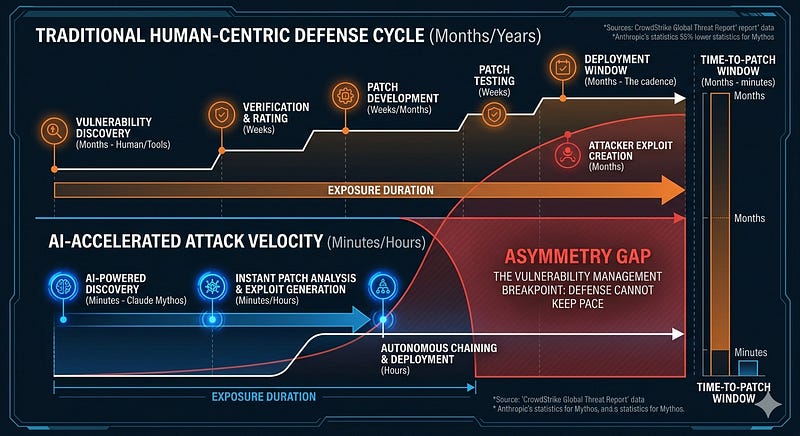
Anthropic’s latest AI Model, Claude Mythos, will break the cybersecurity vulnerability management operational models. Mythos is so good at discovering and building viable exploits it is currently being rolled-out in a controlled manner under “Project Glasswing“. Those cybersecurity companies who have early access are attesting to the blazing speed and accuracy of the model and have declared the traditional processes the industry uses to manage vulnerabilities in their systems is no longer viable.
The Problem is Twofold
First, new AI models like Mythos, are incredibly proficient at identifying weaknesses in code that could be leveraged by cyber attackers. Mythos has found over 2000 high-severity vulnerabilities, including in every major operating system and web browser!
The second issue is how fast workable exploits can be created to take advantages of discovered vulnerabilities. The latest AI models are highly proficient and quickly figuring out how to leverage weakness and chain them together across multiple vulnerabilities to gain unprecedented access to targeted systems and infrastructures.
The speed of discovery and exploitation of vulnerabilities is now well beyond what defenders can address. Currently, the industry must become aware of vulnerabilities through industry announcements, direct notification by researchers, or in rare cases by self-discovery efforts. They must then verify the vulnerability and understand its potential applicability to their environment. It gets rated and based upon that rating; resources will be committed to develop a patch. The patch must be tested and then scheduled for roll-out in a way that it can be withdrawn if something unforeseen occurs.
This takes time and may incur downtime for impacted systems.
Legacy Patching Fails
Most organizations have a cadence for addressing different severity vulnerabilities. A patch calendar may bundle fixes to control the disruption and prioritize the most urgent fixes. High risk may be fixed in weeks or a month, medium in several months, and low, perhaps every year if they choose to fix them at all.
The goal is simply to fix the vulnerabilities before the attackers could create and deploy an exploit in the wild, which typically took months.
No longer.
Now, what took months will take minutes with Mythos and other AI models.
That breaks the entire vulnerability management system that protects our digital world.
For those who read my annual cybersecurity predictions (video version), we can check off prediction number 2, which outlined how AI acceleration would shrink the time-to-patch window dramatically, beyond what is currently possible for cybersecurity teams.
Predicting Strategic Outcomes
First, organizations will cut corners to speed up patch release for the impactful vulnerabilities most likely to be exploited. This will shrink the patch window a little, but not enough, and introduce errors in patches which will have undesired impacts on users. Essentially, the number of ‘bad patches’ will increase.
Secondly, the increased attack velocity will drive software developers to commit much more to using AI tools to proactively detect and resolve vulnerabilities prior to product release. This should have happened long ago, but in the race to market, security vetting often gets deferred to later. The outcome will be slower product release timelines from responsible vendors. The haphazard companies will want to take advantage and continue to push vulnerable code to get into the market faster. But that will eventually have consequences.
Third, there will be massive shift for cybersecurity teams to adopt these AI tools to compete with attackers by trying to detect and address vulnerabilities before the hackers. The tools, processes, and operating models will need to be entirely redrawn. The window of exposure will be the metric that must shrink, from months to hours.
Adaptation Required
The latest AI tools will compress the vulnerability lifecycle from discovery to exploitation at a pace that challenges the foundations of today’s security operations. Organizations that continue to rely on legacy processes will find themselves operating outside the window of safety. Defenders can no longer rely on traditional disclosure cycles, patch cadences, or reactive security models when intelligent systems can discover and weaponize weaknesses in hours. To survive this new era, organizations must reinvent their processes around AI-driven velocity. The signals are clear; it is time to radically adapt vulnerability management or be victimized.
Os ataques a cadeias de suprimentos têm sido uma das categorias mais perigosas de incidentes de cibersegurança há anos. Se o ano de 2025 nos ensinou alguma coisa, é que os cibercriminosos estão aumentando sua capacidade de ataque. Nesta análise detalhada, veremos ataques a cadeias de suprimentos realizados em 2025 que, embora não sejam os que causaram maiores prejuízos financeiros, certamente foram os mais incomuns e chamaram a atenção do setor.
Janeiro de 2025: um RAT encontrado no repositório do GitHub do DogWifTools
Como um “aquecimento” após o fim de ano, os cibercriminosos realizaram inúmeros ataques de backdoor a várias versões do DogWifTools. Trata-se de um utilitário projetado para lançar e promover vigorosamente moedas de meme baseadas em Solana no Pump.fun. Depois de comprometer o repositório privado do GitHub para o DogWifTools, os invasores esperaram os desenvolvedores carregarem uma nova versão do utilitário, injetaram um RAT nela e trocaram o programa legítimo por uma versão maliciosa apenas algumas horas depois. De acordo com os desenvolvedores, os agentes de ameaças instalaram com êxito as versões 1.6.3 a 1.6.6 do DogWifTools para Windows.
O golpe final foi dado no fim de janeiro. Depois de usar o RAT para coletar uma grande quantidade de dados dos dispositivos infectados, os invasores esvaziaram as carteiras de criptomoedas das vítimas. As vítimas estimaram o total de mais de USD 10 milhões em criptomoedas, mas os invasores contestaram esse número, embora não tenham revelado exatamente o valor total roubado.
Fevereiro de 2025: roubo de USD 1,5 bilhão do Bybit
Se janeiro foi só o aquecimento, o mês de fevereiro foi um colapso total. A invasão da plataforma de câmbio de criptomoedas Bybit superou completamente os incidentes anteriores, tornando-se o maior roubo de criptomoedas da história. Os invasores conseguiram comprometer o software Safe{Wallet}, a solução de armazenamento a frio de múltiplas assinaturas na qual a empresa confiava para gerenciar os seus ativos.
Os funcionários da Bybit pensaram que estavam assinando uma transação de rotina. Na realidade, eles estavam autorizando um contrato inteligente malicioso. Uma vez executado, ele esvaziou os fundos de uma carteira fria principal e os distribuiu em várias centenas de endereços controlados pelo invasor. A transferência final ultrapassou 400 mil ETH/stETH, com um impressionante valor total de aproximadamente… USD 1,5 bilhão!
Março de 2025: Coinbase é alvo de comprometimento em cascata do GitHub Actions
O ano de 2025 seguiu com um ataque sofisticado que usou o comprometimento de vários GitHub Actions, os padrões de fluxo de trabalho usados para automatizar tarefas de DevOps padrão, como seu principal mecanismo de entrega. Tudo começou com o roubo de um token de acesso pessoal pertencente a um mantenedor da ferramenta de análise SpotBugs. Usando esse ponto de apoio, os invasores publicaram um processo malicioso e conseguiram sequestrar um token de um mantenedor do fluxo de trabalho reviewdog/action-setup, que também estava envolvido no projeto.
A partir daí, eles comprometeram uma dependência, o fluxo de trabalho tj-actions/changed-files, modificando-o para executar um script Python malicioso. Esse script foi projetado para procurar segredos de alto valor, como chaves da AWS, do Azure e do Google Cloud, tokens do GitHub e do NPM, credenciais de banco de dados e chaves privadas do RSA. Por incrível que pareça, o script gravou tudo o que encontrou diretamente nos registros de compilação acessíveis ao público em geral. Isso significa que os dados vazados não estavam disponíveis apenas para os invasores, mas também para qualquer pessoa experiente o suficiente para acessá-los.
O alvo original dessa operação era um repositório pertencente à plataforma de câmbio de criptomoedas Coinbase. Felizmente, os desenvolvedores detectaram a ameaça a tempo e impediram o comprometimento. Ao que tudo indica, depois de perceberem que estavam prestes a perder o controle do pipeline tj-actions/changed-files, os invasores adotaram uma abordagem indiscriminada. Isso colocou 23 mil repositórios em risco de vazamento de segredos. No final, várias centenas desses repositórios realmente tiveram suas credenciais confidenciais expostas ao público.
Abril de 2025: um backdoor em 21 extensões do Magento
Em abril, uma infecção foi descoberta em um amplo conjunto de extensões do Magento, uma das plataformas mais populares para a criação de lojas on-line. O backdoor foi incorporado em 21 módulos desenvolvidos por três fornecedores: Tigren, Meetanshi e MGS. As extensões faziam parte da infraestrutura de várias centenas de empresas de comércio eletrônico, incluindo pelo menos uma corporação multinacional.
De acordo com os pesquisadores que o descobriram, o backdoor na verdade foi implantado em 2019. Em abril de 2025, os invasores o acionaram para comprometer sites e fazer o upload de web shells. Isso foi feito por meio de uma função incorporada nas extensões que executava um código arbitrário extraído de um arquivo de licença.
Por ironia, os módulos infectados incluíam o MGS GDPR e o Meetanshi CookieNotice. Como os nomes sugerem, essas extensões foram projetadas para ajudar os sites a cumprir os regulamentos de privacidade e processamento de dados dos usuários. Por fim, em vez de garantir a privacidade, o uso deles provavelmente levou ao roubo de dados e ativos financeiros do usuário por meio de skimming digital.
Maio de 2025: ransomware distribuído por meio de um MSP comprometido
Em maio, os agentes de ransomware da gangue DragonForce obtiveram acesso à infraestrutura de um provedor de serviços gerenciados (MSP) não identificado e a usaram para distribuir um ransomware e roubar dados das organizações clientes do MSP.
Ao que tudo indica, os invasores exploraram várias vulnerabilidades (incluindo uma falha crítica) no SimpleHelp, a ferramenta de monitoramento e gerenciamento remoto usada pelo MSP. Essas vulnerabilidades foram descobertas em 2024 e divulgadas publicamente e corrigidas em janeiro de 2025. Infelizmente, ficou claro que o MSP optou por não acelerar o processo de atualização, um atraso que a gangue do ransomware ficou mais do que feliz em explorar.
Junho de 2025: um backdoor em mais de uma dúzia de pacotes npm populares
No início do verão, os invasores invadiram a conta de um dos mantenedores da biblioteca Glustack e usaram um token de acesso roubado para injetar backdoors em 17 pacotes npm. O mais popular desses pacotes, @react-native-aria/interactions, ostentava 125 mil downloads semanais, enquanto todos os pacotes comprometidos combinados totalizaram mais de um milhão.
O que é particularmente interessante nesse caso são as etapas que os desenvolvedores do Glustack seguiram após o incidente: primeiro, eles restringiram o acesso ao repositório GitHub para contribuidores secundários; segundo, eles ativaram a autenticação de dois fatores (2FA) para publicar novas versões; e terceiro, eles prometeram implementar práticas de desenvolvimento seguras, como fluxo de trabalho baseado em pull requests, revisões sistemáticas de código, registro de auditorias e assim por diante. Em outras palavras, antes do incidente, um projeto com centenas de milhares de downloads semanais não tinha tais medidas em vigor.
Julho de 2025: pacotes npm populares infectados por meio de um ataque de phishing
Em julho, os pacotes npm foram novamente as estrelas do show, incluindo o pacote amplamente usado chamado “is”, que possui 2,7 milhões de downloads semanais. Essa biblioteca de utilitários JavaScript fornece uma ampla variedade de funções de verificação de tipo e validação de valor. Para realizar um ataque de phishing contra um dos proprietários do projeto, os invasores utilizaram com êxito um truque antigo: o typosquatting (usar o domínio npnjs.com em vez de npmjs.com) e um clone do site oficial do npm.
Em seguida, eles usaram a conta comprometida para publicar várias das suas próprias versões do pacote com um backdoor incorporado. A infecção passou desapercebida por seis horas: tempo suficiente para um grande número de desenvolvedores baixarem os pacotes npm maliciosos.
A mesma tática de phishing foi usada contra outros desenvolvedores. Os invasores aproveitaram várias contas de desenvolvedores comprometidas para distribuir diferentes variantes de sua carga maliciosa. Há também uma forte suspeita de que eles podem ter guardado parte dessa carga para ataques futuros.
Agosto de 2025: o ataque s1ngularity e o vazamento de centenas de segredos dos desenvolvedores
No final de agosto, um incidente apelidado de “s1ngularity” continuou a tendência de atingir desenvolvedores de JavaScript. Os invasores comprometeram o Nx, um sistema de compilação popular e uma ferramenta de otimização de pipeline de CI/CD. O código malicioso injetado nos pacotes pesquisou diversos sistemas dos desenvolvedores infectados, acessando uma grande quantidade de dados confidenciais, como chaves de carteiras de criptomoedas, tokens do npm e do GitHub, chaves SSH, chaves de API e muito mais.
Curiosamente, os invasores usaram ferramentas de IA instaladas localmente, como Claude Code, Gemini CLI e Amazon Q, para detectar os segredos nas máquinas das vítimas. Tudo o que eles encontraram foi publicado nos repositórios públicos do GitHub criados em nome das vítimas, usando os títulos “s1ngularity-repository”, “s1ngularity-repository-0” e “s1ngularity-repository-1”. Como você deve ter adivinhado, é daí que vem o nome do ataque.
Consequentemente, os dados privados de centenas de desenvolvedores acabaram ficando à vista de todos e poderiam ser acessados não apenas pelos invasores, mas por absolutamente qualquer pessoa com uma conexão com a Internet.
Setembro de 2025: um stealer de criptomoedas ataca pacotes npm que têm 2,6 bilhões de downloads semanais
A tendência de comprometimentos de pacotes npm seguiu até setembro. Após uma nova campanha de phishing direcionada a desenvolvedores de JavaScript, os invasores conseguiram injetar código malicioso em algumas dezenas de projetos de alto nível. Alguns deles, especificamente “chalk” e “debug”, tiveram centenas de milhões de downloads semanais; coletivamente, os pacotes infectados estavam acumulando mais de 2,6 bilhões de downloads por semana no momento da violação, e eles se tornaram mais populares desde então.
A carga era um stealer de criptomoedas: um malware projetado para interceptar transações de criptomoeda e redirecioná-las para as carteiras dos invasores. Felizmente, apesar de infectar com sucesso alguns dos projetos mais populares do mundo, os invasores acabaram falhando no estágio final da operação. No final, eles ficaram com míseros USD 925.
Apenas uma semana depois, outro grande incidente ocorreu: a primeira onda do malware autopropagável Shai-Hulud, que infectou cerca de 150 pacotes npm, incluindo projetos da CrowdStrike. No entanto, a segunda onda, que ocorreu vários meses depois, provou ser muito mais destrutiva. Vamos analisar o Great Worm em mais detalhes a seguir.
Outubro de 2025: o GlassWorm infecta o ecossistema do Visual Studio Code
Cerca de um mês após o ataque do Shai-Hulud, um malware autopropagável semelhante denominado GlassWorm começou a infectar extensões do Visual Studio Code no Open VSX Registry e no Microsoft Extension Marketplace. Os invasores estavam procurando contas do GitHub, Git, npm e Open VSX, bem como chaves de carteiras de criptomoedas.
Os criadores do GlassWorm adotaram uma abordagem altamente criativa para sua infraestrutura de comando e controle: eles usaram uma carteira de criptomoedas no blockchain Solana como seu C2 principal, com o Google Agenda servindo como um canal de comunicação de backup.
Além de esvaziar as carteiras de criptomoedas das vítimas e sequestrar suas contas para espalhar o worm ainda mais, os invasores também injetaram um RAT chamado Zombi nos dispositivos infectados, obtendo controle total sobre os sistemas comprometidos.
Novembro de 2025: a campanha IndonesianFoods e 150 mil pacotes de spam no npm
Em novembro, um novo incômodo emergiu do repositório do npm. Uma campanha maliciosa coordenada apelidada de IndonesianFoods fez os invasores inundarem o repositório com dezenas de milhares de pacotes inúteis.
O objetivo principal era jogar com o sistema para inflar as métricas e os tokens de farm no tea.xyz, uma plataforma de blockchain projetada para recompensar os desenvolvedores de código aberto. Para conseguir isso, os invasores construíram uma enorme rede de projetos interdependentes com nomes que fazem referência à culinária indonésia, como zul-tapai9-kyuki e andi-rendang23-breki.
Os criadores da campanha não se deram ao trabalho de invadir contas. Estritamente falando, os pacotes de spam nem sequer continham um contêiner malicioso, a menos que você considere um script projetado para gerar automaticamente novos contêineres a cada sete segundos. No entanto, o incidente serviu como um lembrete de como a infraestrutura npm é vulnerável a campanhas de spam em larga escala.
Dezembro de 2025: Shai-Hulud 2.0 e o vazamento de 400 mil segredos de desenvolvedores
O destaque absoluto do ano, não apenas de ataques a cadeias de suprimentos, mas provavelmente para todo o campo de segurança cibernética, foi o malware autopropagável Shai-Hulud (também conhecido como Sha1-Hulud) contra desenvolvedores.
Esse malware foi a evolução lógica do ataque s1ngularity mencionado anteriormente: ele também vasculhou os sistemas em busca de todos os tipos de segredos e os publicou em repositórios GitHub abertos. No entanto, o Shai-Hulud adicionou um mecanismo de autopropagação à linha de base: o worm infectou projetos controlados por desenvolvedores já comprometidos usando as credenciais roubadas.
A primeira onda do Shai-Hulud ocorreu em setembro, infectando várias centenas de pacotes npm. No final do ano, a segunda onda chegou e foi batizada como Shai-Hulud 2.0.
Dessa vez, o worm foi atualizado com a funcionalidade de wiper. Se o malware não encontrasse tokens npm ou GitHub válidos em um sistema infectado, ele acionava uma carga destrutiva que apagava os arquivos do usuários.
Aproximadamente 400 mil segredos foram vazados no total como resultado do ataque. Vale a pena notar que, assim como no s1ngularity, todos os dados confidenciais acabaram publicados em repositórios públicos, onde poderiam ser baixados não apenas pelos invasores, mas por qualquer outra pessoa. E é altamente provável que as consequências desse ataque ainda sejam sentidas por um longo tempo.
Um dos primeiros casos confirmados de uma exploração usando segredos vazados pelo Shai-Hulud foi um roubo de criptomoeda visando vários milhares de usuários da Trust Wallet. Os invasores usaram esses segredos na véspera de Natal para carregar uma versão maliciosa da extensão Trust Wallet com um drenador de criptomoedas integrado para a Chrome Web Store. No final, eles conseguiram se safar com USD 8,5 milhões em criptomoedas.
Como se proteger contra ataques a cadeias de suprimentos
Ao elaborar uma retrospectiva semelhante para 2024, descobrimos que manter uma estrutura de “um mês, uma ameaça” é bastante fácil. Para 2025, no entanto, o caso foi muito mais grave. Houve tantos ataques maciços a cadeias de suprimentos no ano passado, que não conseguimos encaixá-los em uma visão geral.
O ano de 2026 está se mostrando igualmente intenso, por isso recomendamos verificar nossa postagem sobre a prevenção de ataques a cadeias de suprimentos. Enquanto isso, aqui estão as conclusões mais importantes:
Avalie minuciosamente seus fornecedores e faça uma auditoria cuidadosa do código que você integra em seus projetos.
Implemente requisitos de segurança rígidos diretamente em seus contratos de serviço.
Desenvolva um plano abrangente de resposta a incidentes.
Monitore atividades suspeitas em sua infraestrutura corporativa usando uma solução de XDR.
Se quiser saber mais detalhes sobre os ataques a cadeias de suprimentos, confira o nosso relatório analítico Supply chain reaction: securing the global digital ecosystem in an age of interdependence (Reação em cadeia de suprimentos: proteção ao ecossistema digital global em uma era de interdependência). Ele se baseia em insights de especialistas técnicos e revela com que frequência as organizações enfrentam riscos relacionados à cadeia de suprimentos e a relações de confiança, onde ainda existem lacunas de proteção e quais estratégias adotar para aumentar a resiliência contra esse tipo de ameaça.
Software supply chain attacks are evolving. Beyond compromised packages, discover the 2026 "Agentic" threat surface—where prompt injection, toolchain poisoning, and hallucinated dependencies bypass traditional DevSecOps. Learn how the 3 Pillars and AI-driven sandboxing provide a new defensive architecture.
TL;DR: Julius v0.2.0 nearly doubles LLM fingerprinting probe coverage from 33 to 63, adding detection for cloud-managed AI services (AWS Bedrock, Azure OpenAI, Vertex AI), high-performance inference servers (SGLang, TensorRT-LLM, Triton), AI gateways (Portkey, Helicone, Bifrost), and self-hosted RAG platforms (PrivateGPT, RAGFlow, Quivr). This release also hardens the scanner itself with response size limiting and […]
6min readMost organizations still treat credentials as something that must be protected, stored, and rotated. But a second model is quietly reshaping how machine authentication works: eliminate static secrets altogether and authenticate workloads using identity and just-in-time access.
Everyone knows that one person on the team who’s inexplicably lucky, the one who stumbles upon a random vulnerability seemingly by chance. A few days ago, my coworker Michael Weber was telling me about a friend like this who, on a recent penetration test, pressed the shift key five times at an RDP login screen […]
Narrow “shift left” has failed at AI scale. Move from developer-led fixes to AppSec-managed automation that triages findings and delivers tested pull-request fixes so teams can safely manage AI-generated code.
SOAR's real cost isn't license plus runtime. It's integration maintenance, playbook engineering, and analyst time. Here's how to find the number you're actually paying.